Solução para Reconhecimento Óptico de Caracteres (OCR)
F.A.Q
Dúvidas frequentes
Como adiciono um diretório além do CGTI para realização do OCR?
Crie o diretório em questão - recomenda-se seguir a estrutura atual, ou seja, /srv/shares/novoSetor/ocr/ - e crie o arquivo .watchmanconfig dentro de “entrada” com o texto {"settle": 10000}. Como também crie os diretórios "saída" e "originais". Após estas etapas, rode o comando de criação das triggers: Pronto, novo diretório para processamento OCR adicionado.
Como testar o OCR para um diretório que eu adicionei?
Apenas copie/envie o PDF para o servidor, fora do diretório .../ocr/entrada/. Então, logado no servidor via linha de comando, copie o PDF para dentro do diretório .../ocr/entrada que você criou anteriormente. O PDF será processado normalmente.
Existe algum log da solução OCR?
O arquivo de LOG presente em /var/log/ocr.log indica o estado de cada arquivo quanto ao seu processamento.
Como sei que o OCR está instalado?
Rode o comando: ocrmypdf --version
Deve aparecer um resultado similiar a: 5.7.0
Mensagens de comando não encontrado indicarão um problema na sua instalação, portanto, revise todas as etapas antes de continuar.
Como sei que o PDF está sendo processado no servidor?
O último estado no LOG para o arquivo em questão deve ser "Processando". Além disso, por meio do comando top, você deverá ver linha(s) com a execução de gs, tesseract ou ocrmypdf. Isto indica que um ou mais arquivos estão sendo processados.
Por que o processamento demora tanto em arquivos grandes?
Quanto maior o número de páginas ou características do documento escaneado, maior o tempo necessário para o processamento.
Existe alguma maneira de acelerar o processamento do PDF?
Incrementando a quantidade de cores e memória principal da sua VM é possível processar os arquivos PDFs em menor tempo.
O arquivo está recebido pela solução OCR mas não está sendo processado, o que pode estar acontecendo?
O watchman pode não estar ativo. Caso isso ocorra, rode o comando watchman watch-list e observe se os processamentos foram iniciados no log da solução OCR. Caso não haja entradas no log, verifique o log do watchman:
$ tail -f /usr/local/var/run/watchman/root-state/log.
Mensagens de erro podem ser consultadas no Google para dúvidas.
Caso o watchman esteja OK e ainda haja problemas para processar o arquivo, verifique se existe disco e memória suficientes para realizar esta operação.
Ao mover um arquivo PDF de dentro do próprio servidor, o OCR funciona. Mas enviando do meu usuário via rede (samba, sftp, outro meio) o OCR não acontece, o que posso verificar?
Problemas de permissão local. Siga as políticas definidas para o acesso aos diretórios e certifique-se de que ao enviar o PDF via rede, as permissões estejam adequadas e ajustadas para atender a sua política adotada no campus.
Adicionalmente, alguns softwares de envio de arquivos, ou mesmos os servidores de arquivos, possuem mecanismos para ajustar as permissões padrão para novos arquivos enviados.
Instalação da solução OCR
1. Introdução
Este documento visa a orientação para a instalação da solução OCR a ser utilizada no Instituto Federal de Pernambuco para reconhecimento óptico de caracteres em documentos digitalizados. Tal tecnologia permite a busca, indexação de arquivos PDF, como também assistência a deficientes visuais por meio de softwares assistivos.
Este documento está estruturado como se segue. A seção 2 descreve as características dos softwares utilizados para a solução, na seção 3 demonstra-se os procedimentos de instalação do OCRmyPDF e demais softwares. A seção 4 apresenta as configurações/modificações necessárias para o funcionamento do sistema, incluindo a configuração da impressora caso a TI opte por esta solução. Na seção 5 é demonstrado o uso da solução, e, finalmente, na seção 6 são apresentadas as referências utilizadas.
Características
- Processamento OCR;
- Texto em língua portuguesa do Brasil;
- Arquivos com saída PDF do tipo PDF/A-1b;
- Possibilidade de monitoramento de um ou mais diretórios de entrada;
- Processamento de PDFs mistos (com texto digital e texto escaneado);
- Processamento de documentos grandes (> 50 pag.);
- Manutenção dos arquivos PDF originais;
- Log para registro do processamento da solução OCR.
2. Softwares utilizados
O sistema operacional recomendado é o Debian a partir da versão 9.
OCRmyPDF
O OCRmyPDF realiza a leitura de documentos escaneados em PDF e permite o reconhecimento do seu texto. Assim, podendo ser buscado e indexado. Além disso, os documentos são automaticamente gerados em formato PDF/A, para arquivamento de longo prazo de documentos eletrônicos. O OCRmyPDF gera documentos no formato PDF/A-1b e PDF/A-2b.
Watchman
O Watchman permite monitorar determinado(s) diretório(s) com o objetivo de realizar operações quando os arquivos são modificados. É possível filtrar os tipos de arquivos com base no nome, tipo, dentre outras características.
Como o OCRmyPDF não funciona com base no esquema de cliente-servidor até o presente momento, é necessário um software como o Watchman para monitorar determinadas entradas e disparar comandos para executar o processamento dos arquivos inseridos ou modificados.
Na imagem seguinte, uma demonstração do fluxo de operação de todo o sistema caso a TI local opte pelo uso de um servidor de arquivos como o Samba.
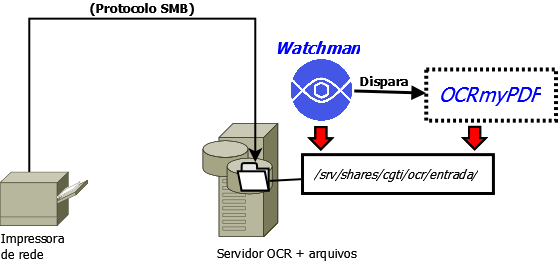
Na imagem seguinte, uma demonstração do fluxo de operação de todo o sistema caso a TI local opte pelo uso de um servidor de SFTP.
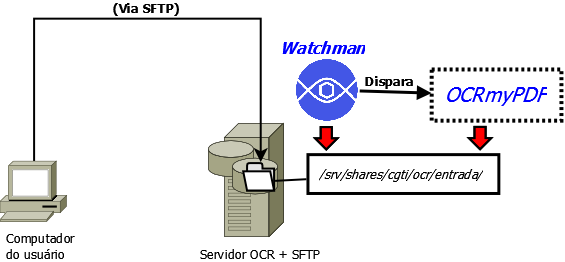
 O método de envio do arquivo para a pasta de entrada não está no escopo desta solução.
O método de envio do arquivo para a pasta de entrada não está no escopo desta solução.
Vozes NextUp-ScanSoft
Se desejar, este é um pacote de fala disponibilizado pela NextUp com uma voz feminina chamada Raquel. Este pacote é destinado ao uso nos clientes e não é necessária sua instalação no lado do servidor OCR. Atualmente, o software não faz mais parte do portfólio da empresa, mas a instalação é permitida e sem custos com o instalador disponível na Web. O pacote é utilizado por softwares como Adobe Reader e Foxit PDF Reader para a leitura do texto.
3. Instalação
OCRmyPDF
A última versão do OCRmyPDF disponível nos repositórios Debian/Ubuntu é bem anterior a versão já disponibilizada no repositório oficial dos desenvolvedores. Assim, não contempla as últimas atualizações necessárias ao bom funcionamento do pacote no que se refere a demanda de OCR do IFPE. Portanto, será demonstrada a instalação via compilação do código fonte.
Logado como root, execute os comandos:
$ apt-get update
$ apt-get install python3-pip
$ apt-get install libffi-dev
$ apt-get install tesseract-ocr
$ apt-get install ghostscript
$ apt-get install qpdf
$ apt-get install git
$ pip3 install git+https://github.com/jbarlow83/OCRmyPDF.gitPara dar suporte ao idioma Português do Brasil, instale o pacote abaixo:
$ apt-get install tesseract-ocr-por -yCom o OCRmyPDF instalado, faça o teste com algum arquivo PDF escaneado:
$ ocrmypdf entrada.pdf saida.pdf --output-type pdfa-1 -l por Os argumentos --output-type pdfa-1 -l por significam respectivamente o tipo de PDF/A gerado e o idioma a ser considerado na interpretação do texto presente no documento PDF.
Watchman
Ainda como root, instale alguns pacotes de dependência:
$ apt-get install gcc
$ apt-get install autoconf
$ apt-get install automake
$ apt-get install build-essential
$ apt-get install libtool
$ apt-get install libssl-dev
$ apt-get install pkg-config
$ apt-get install python-dev
$ apt-get install python3-devAgora procede-se a instalação do Watchman (como root):
$ git clone https://github.com/facebook/watchman.git
$ cd watchman
$ git checkout v4.9.0
$ ./autogen.sh
$ ./configure
$ make
$ make installNextUp-ScanSoft Raquel
Apenas baixe e instale o software (Windows) por meio do link abaixo:
|
https://drive.google.com/file/d/0B3aNFZuG_Yw9cjRCNUJBOUQ3QVk/view?usp=sharing |
Desinstalação
Caso seja necessário remover alguns dos softwares para manutenção/atualização, realize os seguintes comandos à seguir. Para remoção do OCRmyPDF:
$ pip3 uninstall ocrmypdfPara a remoção do Watchman, seria necessário excluir os binários, portanto, não se recomenda esta prática. Entretanto, caso necessite atualizar o Watchman, basta realizar a nova instalação que os binários serão sobrescritos com a nova versão.
4. Configuração
A configuração para a solução OCR fica praticamente com o Watchman e a impressora, já que a utilização do OCRmyPDF é bem simples. Considere a seguinte estrutura:
root@t-ifpe-ocr-beta:/# tree /srv
/srv
└── shares
├── ascom
│ └── ocr
│ ├── entrada
│ ├── originais
│ └── saida
├── cgti
│ └── ocr
│ ├── entrada
│ ├── originais
│ └── saida
└── dae
└── ocr
├── entrada
├── originais
└── saida
Watchman
O Watchman irá monitorar todos os diretórios “entrada” e dispara um script quando um novo arquivo PDF for criado. No exemplo abaixo, iremos criar três triggers. Para cada diretório “entrada”, crie o diretório e em seguida o seguinte arquivo de configuração do Watchman, exemplo para cgti:
$ mkdir -p /srv/shares/cgti/ocr/entrada/
$ mkdir -p /srv/shares/cgti/ocr/saida/
$ mkdir -p /srv/shares/cgti/ocr/originais/
$ nano /srv/shares/cgti/ocr/entrada/.watchmanconfig
{"settle": 10000}Sobre os diretórios criados, é importante trabalhar corretamente as permissões de usuário e grupo de acordo com o seu serviço de rede e políticas de acesso.
A função do arquivo .watchmanconfig é passar configurações específicas do diretório ao watchman. Neste caso, a opção "settle" impede que o PDF seja processado antes de sua completa transferência para o diretório. Crie em cada diretório "entrada" antes de executar o próximo comando de criação dos triggers.
Os triggers são criados e invocam o script no diretório /srv/ - o script pode estar em outro local, só necessita de permissão de execução do root. Crie as triggers:
$ watchman -- trigger /srv/shares/cgti/ocr/entrada/ 'ocrTrigCgti' '*.pdf' -- /srv/doOcr.sh
$ watchman -- trigger /srv/shares/dae/ocr/entrada/ 'ocrTrigDae' '*.pdf' -- /srv/doOcr.sh
$ watchman -- trigger /srv/shares/ascom/ocr/entrada/ 'ocrTrigAscom' '*.pdf' -- /srv/doOcr.shDetalhes:
Agora observe o script que está sendo utilizado, copie e cole no mesmo caminho, ou seja, /srv/doOcr.sh:
#!/bin/bash
# Escreve no log. Recebe o nome do arquivo e a ação realizada.
logIt(){
echo -e "$(date +%d/%m/%Y-%T)\t" $1"\t"$2 >> /var/log/ocr.log
}
# Realiza o OCR. Recebe o nome do arquivo de entrada.
ocrFile(){
logIt "$arg" "Processando"
filename=$(echo "$1" | cut -f 1 -d '.') # sem extensão
entrada="$1"
saida="$filename"-ocr.pdf
ocrmypdf "$entrada" ../saida/"$saida" -l por --output-type pdfa-1 --skip-text
chmod g=rw,o= ../saida/"$saida"
logIt "$arg" "OCR realizado"
mv "$arg" ../originais
}
# Fluxo principal
for arg in "$@"
do
if [ -f "$arg" ]; # arquivo existe ?
then
logIt "$arg" "Arquivo recebido"
ocrFile "$arg" &
fi
doneCaso copie e cole o script acima, antes, edite o texto e organize as linhas e aspas duplas (“ ”).
Dê permissões de execução para o script.
$ chmod +x /srv/doOcr.shAtivando a auto-inicialização
O watchman deve monitorar os diretórios assim que o S.O. for iniciado. De forma a permitir que esta função seja realizada, deve-se adicionar o comando de inicialização do watchman aos comandos executados após o início do S.O.
Para realizar isto, basta seguir o tutorial de scripts de inicialização com system V que está na WIKI do IFPE. Atente para as variáveis do script que neste caso do watchman devem ser:
dir="/usr/local/bin/"
cmd="watchman -f"
user="root"
Impressora
Será demonstrada configuração na impressora Kyocera FS-1135 enviando o PDF para um servidor de arquivos. Para outras impressoras, as configurações são semelhantes, com algumas pequenas diferenças que podem ocorrer na forma como o S.O. da impressora trata os dados inseridos.
A impressora deve estar conectada diretamente à rede.
Acesse o painel WEB da impressora:

Serão criados “contatos” na agenda da impressora com configurações pré-definidas para salvar os documentos escaneados. Desta forma, evita-se a inserção manual das configurações de acesso ao servidor de arquivos. Na Kyocera, por exemplo, um contato pode conter informações FTP, SMB e de e-mail para o envio do PDF gerado.

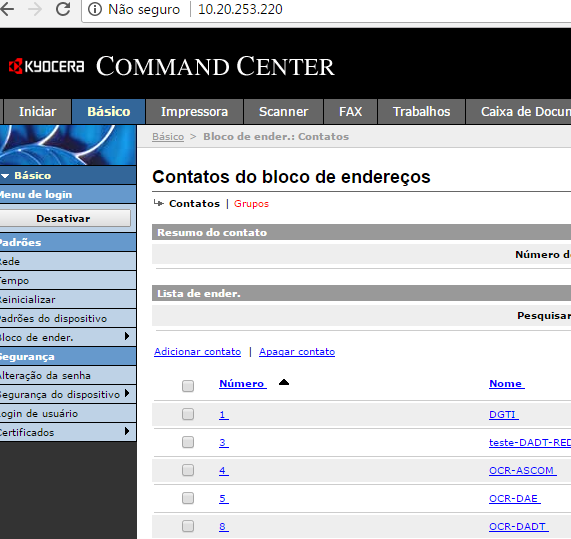
Tem-se várias opções de envio, será escolhido o protocolo SMB.

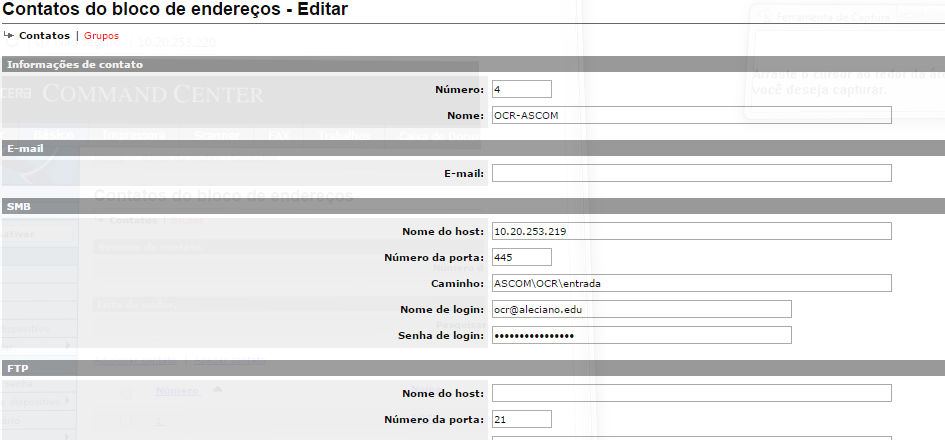
-
Nome de host: IP ou hostname do servidor de arquivos;
-
Número da porta: porta que o servidor de arquivos escuta para receber arquivos;
-
Caminho: utilizando contra-barras, o nome do compartilhamento seguido dos sub-diretórios para onde serão enviados os arquivos PDF;
-
Nome de login: usuário e DOMÍNIO no formato usuario@dominio. Recomenda-se a criação de um usuário no seu domínio para cada impressora.
-
Senha de login: senha do usuário no DOMÍNIO.
Clicar em Enviar para salvar as configurações. Posteriormente, para escanear e mandar para o servidor de arquivos, seguir as próximas configurações.
Envio dos arquivos
A configuração do envio dos arquivos foge do escopo deste tutorial. Mas o importante é que os usuários criados para o envio dos arquivos tenham permissões de escrita (write) no diretório “entrada” configurado. O script (/srv/doOcr.sh) deve ter configurações de execução habilitadas para que o Watchman consiga dispará-lo, bem como os usuários do domínio devem ter no mínimo acesso de leitura no diretório de “saída”.
Recomenda-se uma política de manutenção dos arquivos que ficarão no diretório originais. Pode-se movê-los para um backup ou executar algum script periódico para limpar arquivos antigos.
LOG
O log de processamento dos arquivos da solução OCR se encontrará disponível no caminho /var/log/ocr.log. O estado possíveis para arquivo é:
- Arquivo recebido - o arquivo foi recebido e detectado pelo watchman que já invocou o script doOcr.sh.
- Processando - o OCRmyPDF está processando o arquivo.
- OCR realizado. - o arquivo foi processado pelo OCRmyPDF com sucesso e movido para o diretório “saida”.
5. Atualização a partir de uma versão anterior
Se já existia uma versão anterior da solução OCR implantada, basta realizar a atualização de alguns pontos.
Atualize o OCRmyPDF:
$ apt-get update
$ apt-get install python3-pip
$ apt-get install libffi-dev
$ apt-get install tesseract-ocr
$ apt-get install ghostscript
$ apt-get install qpdf
$ apt-get install git
$ pip3 install git+https://github.com/jbarlow83/OCRmyPDF.git@v5.7.0
$ apt-get install tesseract-ocr-por -yDelete as triggers antigas do watchman, exemplo para cgti:
$ watchman watch-del /srv/shares/cgti/ocr/entradaCrie o arquivo .watchmanconfig no(s) diretório(s) de entrada do OCR, exemplo para cgti:
$ nano /srv/shares/cgti/ocr/entrada/.watchmanconfig
{"settle": 10000}Faça uma cópia e atualize o script de execução doOcr.sh para esta versão abaixo:
$ cp /srv/doOcr.sh /srv/doOcr.sh-bkp
$ nano /srv/doOcr.sh
<<<<<<<<<insira o conteúdo abaixo>>>>>>>>>>>>>>>>>>>>>>>
#!/bin/bash
# Escreve no log. Recebe o nome do arquivo e a ação realizada.
logIt(){
echo -e "$(date +%d/%m/%Y-%T)\t" $1"\t"$2 >> /var/log/ocr.log
}
# Realiza o OCR. Recebe o nome do arquivo de entrada.
ocrFile(){
logIt "$arg" "Processando"
filename=$(echo "$1" | cut -f 1 -d '.') # sem extensão
entrada="$1"
saida="$filename"-ocr.pdf
ocrmypdf "$entrada" ../saida/"$saida" -l por --output-type pdfa-1 --skip-text
chmod g=rw,o= ../saida/"$saida"
logIt "$arg" "OCR realizado"
mv "$arg" ../originais
}
# Fluxo principal
for arg in "$@"
do
if [ -f "$arg" ]; # arquivo existe ?
then
logIt "$arg" "Arquivo recebido"
ocrFile "$arg" &
fi
doneCrie novamente as triggers do watchman, exemplo para cgti:
$ watchman -- trigger /srv/shares/cgti/ocr/entrada/ 'ocrTrigCgti' '*.pdf' -- /srv/doOcr.sh6. Operação com scanner
Aqui é demonstrado o envio dos arquivos de uma impressora para o servidor de arquivos local.
Scanner


Apertar o botão “Enviar”.


Apertar o botão de contatos, ou “Libro de direcciones” como neste caso. Tem a função de acesso a Agenda.


Selecione o contato previamente salvo na agenda e apertão o botão “Ok”.

Aperte “Ok” para confirmar o endereço. Em seguida, apertar o botão verde principal para dar início a digitalização.

Se não aparecer nenhuma mensagem de erro ou o LED vermelho não piscar, houve sucesso no escaneamento.
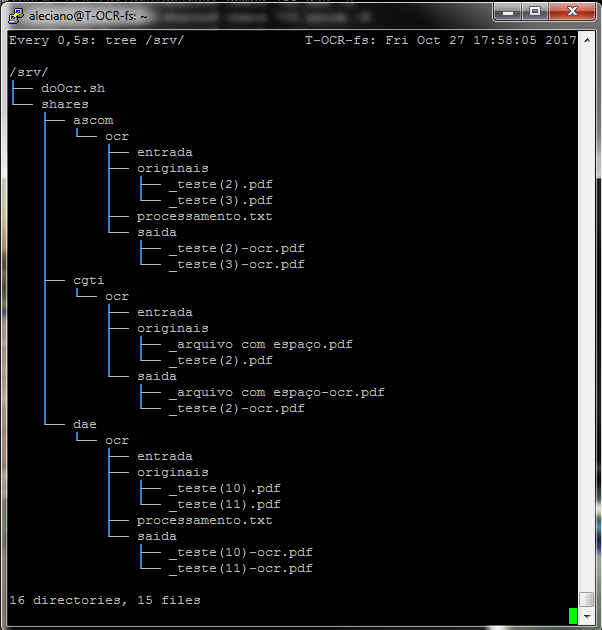
Diretório “Ascom”, na estrutura, indicando sucesso no escaneamento e no processamento OCR.
O OCRmyPDF pode levar alguns minutos para processar o arquivo PDF.
Visualização (texto)
O arquivo com reconhecimento OCR e padrão PDF/A-1b ou 2b, aparece da seguinte forma em softwares como Adobe Reader. Como é possível notar, o texto é selecionável.
Visualização (áudio da leitura)
Utilizando o software Adobe Reader como exemplo, acesse as Preferências do software, ative o recurso de Leitura do texto e selecione a voz “Raquel” para uso.
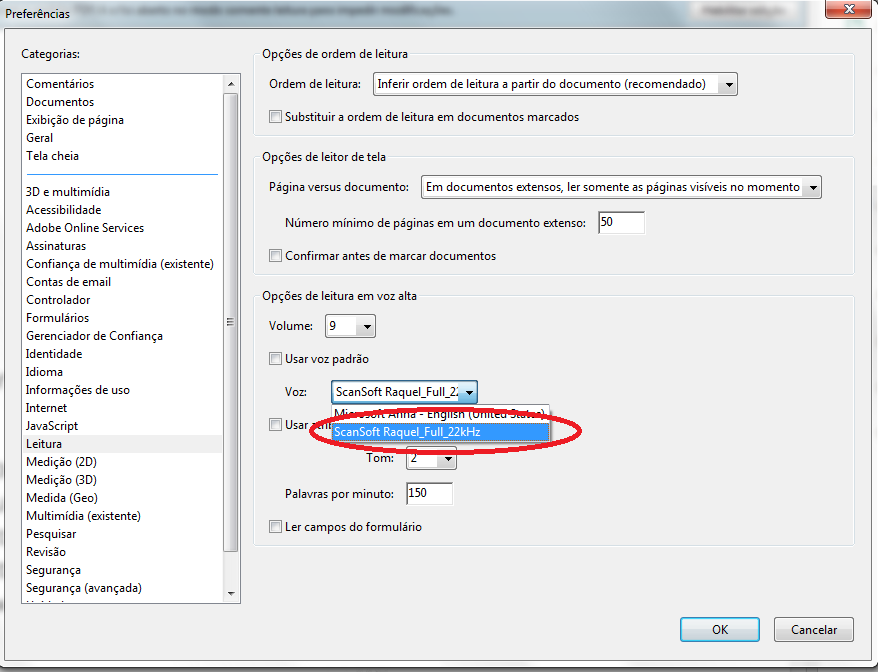
Para escutar a leitura do texto pelo software, pressione os atalhos Shift + Ctrl + Y (Ativar leitura em voz alta) e Shift + Ctrl + B (Ler todo o documento). Também, é possível escutar clicando no texto ou percorrendo com o cursor do mouse.
Leitura do arquivo com OCR em ação:


https://www.youtube.com/watch?v=xrBu4fhoXFE&feature=youtu.be
7. Referências
https://pt.wikipedia.org/wiki/PDF/A
https://softwarepublico.gov.br/archives/thread/sei-negocio/como-criar-pdfa-conforme-iso-19005-12005
https://ocrmypdf.readthedocs.io/en/latest/index.html
http://facebook.github.io/watchman/
https://stackoverflow.com/questions/1659147/how-to-use-ghostscript-to-convert-pdf-to-pdf-a-or-pdf-x
https://www.pdf-online.com/osa/validate.aspx
http://www.tecassistiva.com.br/servicos?id=105
Solução OCR em OVA
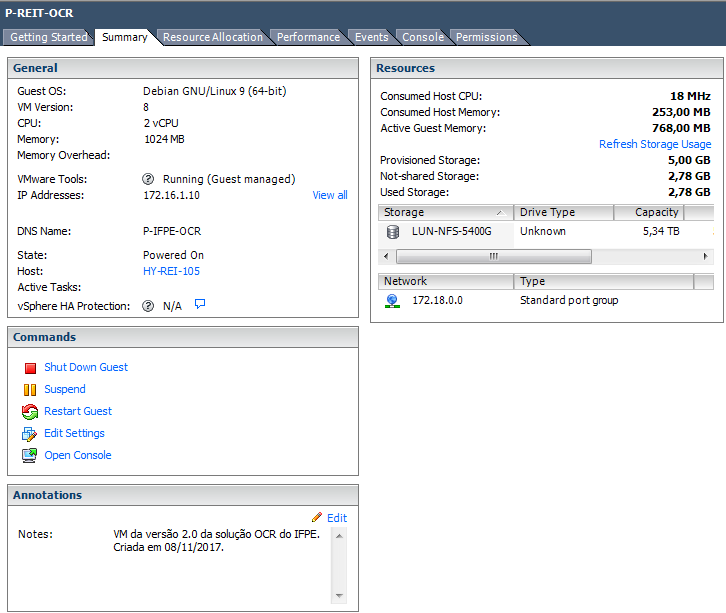
Introdução
Este documento visa a orientação sobre as configurações aplicadas na máquina virtual (VM) da solução OCR versão 1.2.1 Serão apresentadas as configurações de sistema, particionamento, rede, usuários e particularidades da solução OCR.
As CGTIs devem alterar configurações para satisfazer suas necessidades locais. A DADT entrega uma versão simplificada e funcional, com exemplos, demonstrando o serviço. À partir da entrega da VM, a CGTI fica responsável por sua manutenção e uso. Não se responsabilizando a DADT por eventuais problemas decorridos de alterações realizadas pelas coordenações locais de TI dos campi.
Características da VM
- VM Version: 8
- CPU: 2 vCPU
- Memória: 1024 MB
- Disco provisionado: 5 GB
O tamanho do disco é pequeno para facilitar o download e implantação da solução. Recomenda-se fortemente que o disco seja expandido para evitar falta de espaço em algumas partições.
- Sistema operacional: Debian 9.1, 64 Bits
- Sistema de armazenamento: LVM (Logical Volume Management). Utilizado por permitir flexibilidade na extensão das partições – útil para quando os discos ficam cheios e for necessário expandi-lo.
O volume físico está em /dev/sda5:
|
$ sudo pvs |
|
PV VG Fmt Attr PSize PFree /dev/sda5 linux lvm2 a-- 4,52g 0 |
Apresenta grupo de volumes (linux) com um volume físico e três volumes lógicos:
|
$ sudo vgs |
|
VG #PV #LV #SN Attr VSize VFree linux 1 3 0 wz--n- 4,52g 0 |
Volumes lógicos são root, srv e swap:
|
$ sudo lvs |
|
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert root linux -wi-ao---- 3,11g srv linux -wi-ao---- 956,00m swap linux -wi-ao---- 488,00m |
Visão geral do sistema de arquivos:
|
$ df -hP |
|
Sist. Arq. Tam. Usado Disp. Uso% Montado em udev 487M 0 487M 0% /dev tmpfs 100M 4,6M 96M 5% /run /dev/mapper/linux-root 3,0G 2,2G 725M 75% / tmpfs 499M 0 499M 0% /dev/shm tmpfs 5,0M 0 5,0M 0% /run/lock tmpfs 499M 0 499M 0% /sys/fs/cgroup /dev/mapper/linux-srv 925M 2,4M 859M 1% /srv /dev/sda1 472M 37M 411M 9% /boot tmpfs 100M 0 100M 0% /run/user/1000 |
- Configurações de rede. Os IPs devem ser trocados de acordo com a rede de cada campi:
|
$ nano /etc/network/interfaces |
|
# A interface de loopback auto lo iface lo inet loopback # A interface de rede primaria auto ens33 allow-hotplug ens33 iface ens33 inet static address 172.16.1.10/24 gateway 172.16.1.1 dns-nameservers 172.16.1.6 dns-search ifpe.edu.br |
Informações das interfaces:
|
$ ip a |
|
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:94:08:8d brd ff:ff:ff:ff:ff:ff inet 172.16.1.10/24 brd 172.16.1.255 scope global ens33 valid_lft forever preferred_lft forever |
- Usuários ativos. Sugere-se a troca das senhas:
|
Usuário |
Senha |
|
cgti |
*@tif0cr |
|
root |
&_p0i3TJ |
Grupos ativos:
|
Grupo |
Usuário membro |
|
cgti |
cgti |
|
root |
root, cgti |
|
sudo |
root, cgti |
- O diretório mapeado como exemplo para OCR é /srv/shares/cgti/ocr/entrada/. A CGTI deve criar os novos diretórios e mapeamentos de acordo com a sua necessidade.
A estrutura dos diretórios:
|
$ tree /srv |
|
/srv └── shares ├── cgti └── ocr ├── entrada ├── originais └── saida |
Trigger do Watchman criada para o diretório em questão:
|
$ cat /usr/local/var/run/watchman/root-state/state |
|
{ "watched": [ { "triggers": [ { "command": [ "/srv/doOcr.sh" ], "expression": [ "anyof", [ "match", "*.pdf", "wholename" ] ], "stdin": [ "name", "exists", "new", "size", "mode" ], "name": "ocrTrigCgti", "append_files": true } ], "path": "/srv/shares/cgti/ocr/entrada" } ], "version": "4.9.0" } |
Arquivo do Watchman para configuração presente de forma obrigatória no diretório “entrada”:
|
$ cat /srv/shares/cgti/ocr/entrada/.watchmanconfig |
|
{"settle": 10000} |
Como importar a VM no ambiente VMWARE
Neste método de importação será utilizado o ambiente vSphere Client versão 6.0.0, disponível em https://kb.vmware.com/s/article/2089791. O ESXi utilizado é da versão 6.5.0. Certifique-se de ter instalado o vSphere Client na sua máquina para ter sucesso neste método.
Baixe a OVA: https://drive.google.com/file/d/1E20S31VW41_Pu9jc_MTfURKJRmmmmi2C/view?usp=sharing
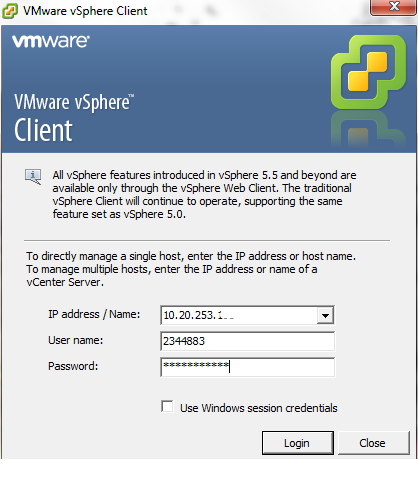
Realize o login no ambiente com suas credenciais:
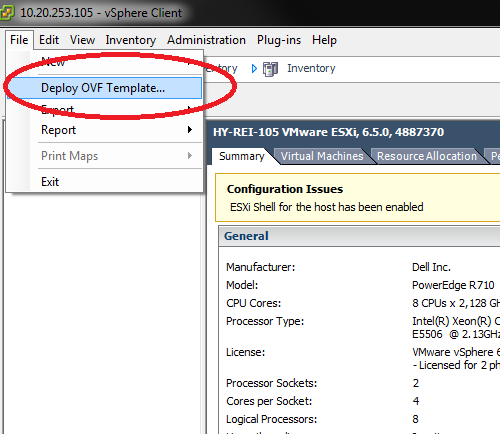
Após logar, clique em File e em seguida, clique Deploy OVF Template:
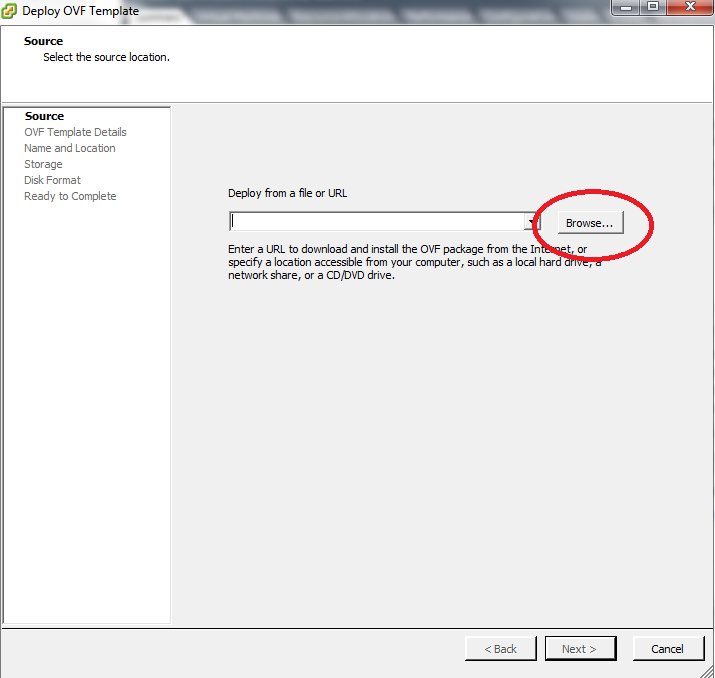
Na próxima janela, clique em Browse para procurar o arquivo OVA:
 <>
<>
Selecione o arquivo e clique em Abrir:

Na próxima janela clique em Next, e observe os detalhes da VM:
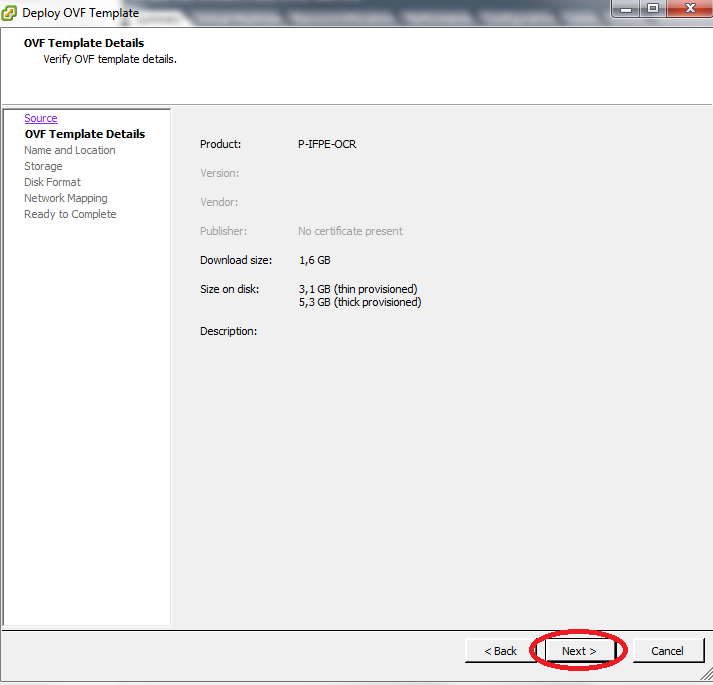
Selecione o nome desejado para VM e clique em Next.
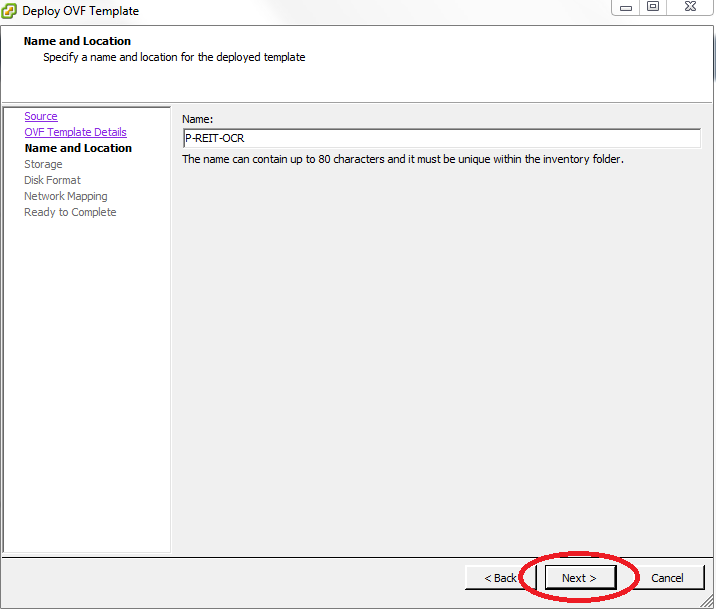
Selecione o storage do ESXi no qual os arquivos do objeto da VM serão armazenados e clique Next. Na janela seguinte, clique Next mais uma vez.
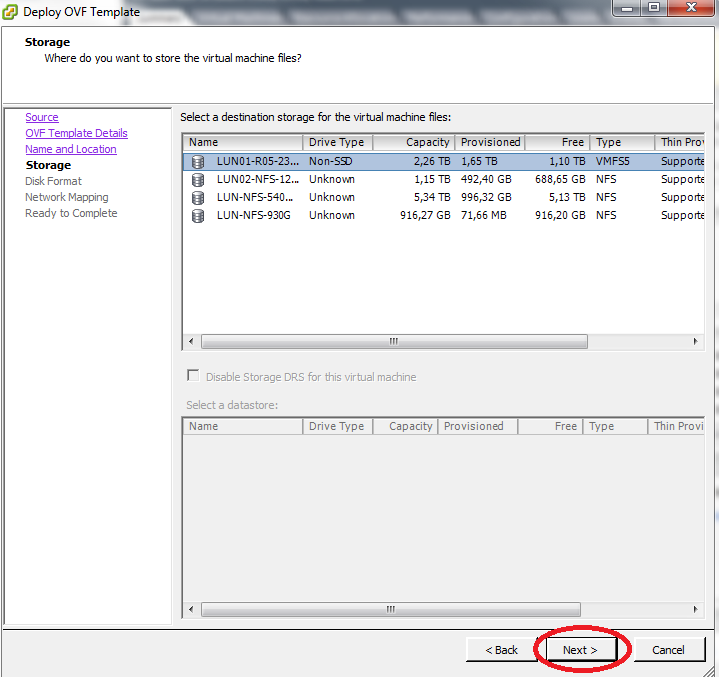
Agora realize o mapeamento da rede interna criada no ESXi. Na coluna Destination Networks deverá existir o nome da rede aplicada no ESXi local, selecione apropriadamente de acordo com o seu ambiente. No caso em tela, a rede de destino possui o mesmo nome.

Estamos quase lá, agora observe as configurações selecionadas. Clique em Finish quando tiver certeza do que será aplicado.
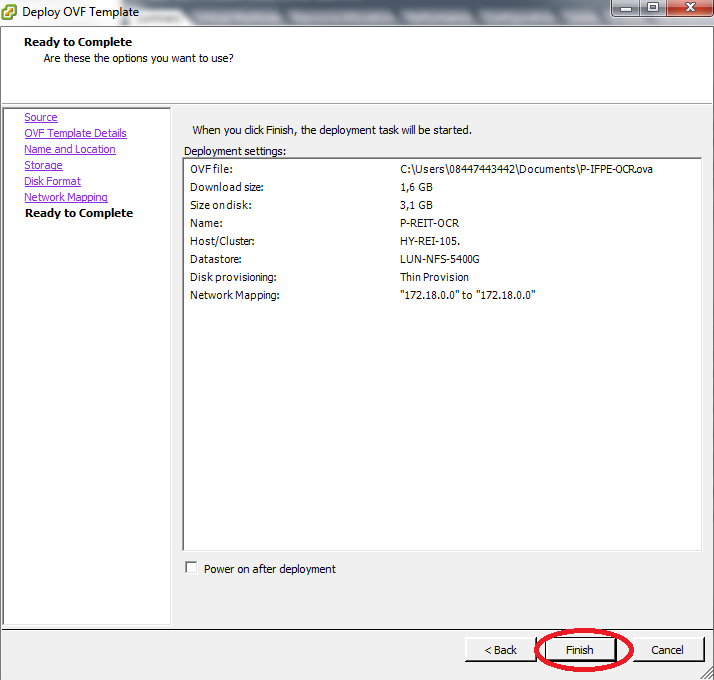
A VM começará a ser importada:
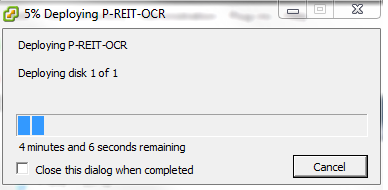
A operação pode levar algum tempo. A seguinte tela surge quando concluído.

Pronto, a VM está pronta para uso.