TI - Infraestrutura e Serviços de Rede
SERVIÇOS:
- Acesso Remoto
- Armazenamento
- Backup
- Certificados SSL
- Monitoramento
- Dell OpenManage: Instalação no Centos 7
- templates-e-scripts
- Zabbix: Importando templates
- Zabbix: Instalando o agente em clientes linux
- Zabbix: Instalando o agente em clientes windows
- Zabbix: Instalando o proxy
- Zabbix: Instalando o servidor
- Zabbix: Templates para o Bacula/Bareos
- Questões e dicas
- Cliente: SSSD
- Servidores: BareOS/Bacula
- Servidores: Samba
- Servidores: SSH
- Sistema: Discos e partições
- Sistema: Rede
- Redes Virtuais Privadas
- Serviços de domínio
- Solução para Reconhecimento Óptico de Caracteres (OCR)
Acesso Remoto
Acesso Remoto Web - Informações
Para esclarecer dúvidas ou solucionar problemas relacionados à plataforma de Acesso Remoto Web, verifique as informações disponíveis nos itens a seguir.
1. Para que serve a plataforma de Acesso Remoto Web?
A plataforma possibilita ao usuário estabelecer uma sessão remota a partir da web, assim, pode ser utilizada para disponibilizar o acesso remoto à aplicações normalmente instaladas em desktops. Dessa forma, será utilizada para acesso ao computador onde estão instalados os sistemas de gestão acadêmica Q-Acadêmico e Q-Biblio (versão desktop) usados no IFPE.
2. O que muda em relação ao acesso remoto realizado até 2020?
Até 2020, realizou-se o acesso ao servidor onde estão instaladas as versões desktop dos sistemas Q-Acadêmico e Q-Biblio a partir de aplicações de sessão remota disponíveis no sistema operacional do computador utilizado pelo usuário. No Microsoft Windows, por exemplo, através da aplicação "Conexão de Área de Trabalho Remota" ![]() .
.
Com a disponibilização da nova plataforma esse acesso será realizado através de um navegador web (Chrome, Edge, Firefox, Opera, etc). Além disso, no novo formato as credenciais utilizadas serão as do provedor de identidade Acesso.IFPE, o que permitirá ao usuário gerenciar e recuperar a senha de forma autônoma e com maior celeridade.
As credenciais do Acesso.IFPE são válidas apenas para acesso ao computador onde as aplicações de gestão acadêmica estão instaladas. Para fazer o login nos sistemas Q-Acadêmico ou Q-Biblio é necessário ter uma conta de usuário e senha de acesso aos mesmos (estas não são geridas pela Diretoria de TI).
3. Como obter as credenciais do Acesso.IFPE, necessárias para entrar na plataforma de Acesso Remoto Web?
Para informações referentes às credenciais do provedor de identidade, verifique o Manual do Acesso.IFPE.
4. Já possuo as credenciais, como faço para entrar na plataforma de Acesso Remoto Web?
A partir do endereço https://acessoremoto.ifpe.edu.br/ realiza-se o acesso à plataforma. Para informações sobre os demais procedimentos, verifique a página do tutorial de utilização.
5. Possuo credenciais válidas do Acesso.IFPE, segui os passos do tutorial da plataforma de Acesso Remoto, mas não consigo entrar no sistema. Como devo proceder?
Caso tenha realizado todos os procedimentos anteriores corretamente e mesmo assim não consiga utilizar a plataforma de Acesso Remoto Web, envie e-mail para suporte.ti@reitoria.ifpe.edu.br com a descrição do seu problema.
Conexão remota ao Q-Acadêmico e Q-Biblio através da web
1. Acessando o sistema através da Web
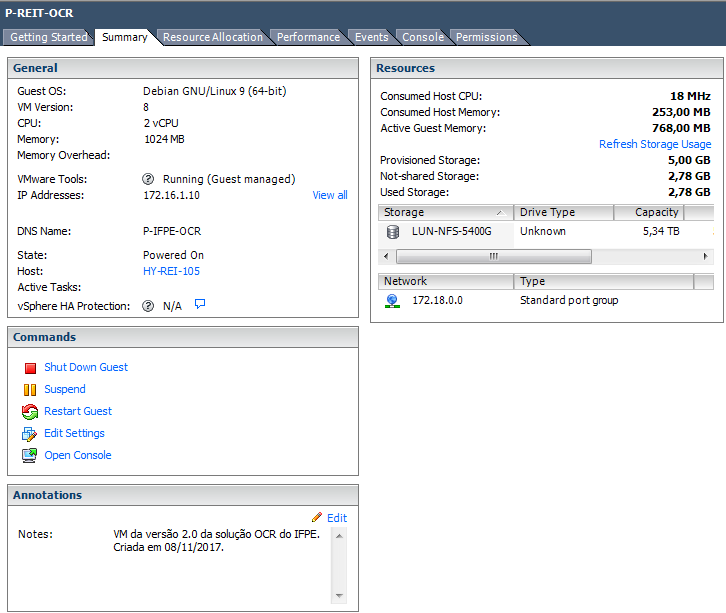
Para acessar o Q-Acadêmico e o Q-Bilbio, através da aplicação web, é preciso acessar o seguinte endereço: https://acessoremoto.ifpe.edu.br como na imagem a seguir.
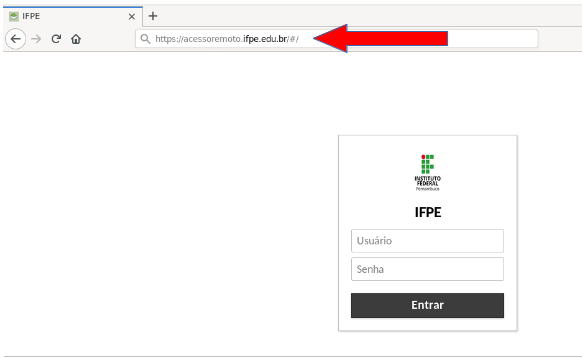
As credenciais do sistema são as mesmas do Acesso IFPE. Digite no campo "Usuário" seu CPF e no campo "senha" a respectiva senha usada no Acesso IFPE. Depois disso, clique em "Entrar"

Depois de autenticar no sistema, a seguinte tela será apresentada ao usuário.

Nessa tela, são apresentadas ao usuário as seguintes opções:
- Todas as conexões - São as conexões que o usuário tem permissão para acessar;
- Conexões recentes - São as últimas conexões acessadas pelo usuário.
Para acessar o Q-Acadêmico e o Q-Biblio, o usuário deverá ir ao menu Todas as conexões e clicar no sinal de [+] para exibir as conexões disponíveis.
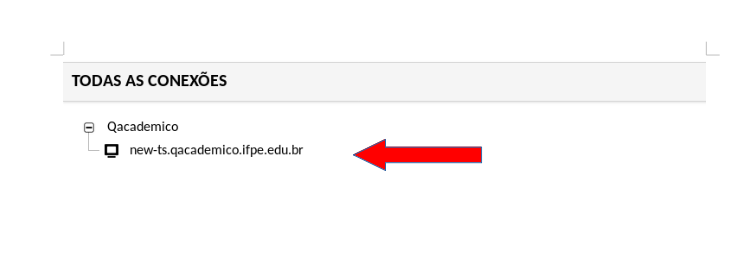
Depois de selecionar a conexão, será aberta uma sessão na máquina selecionada como na imagem a seguir.
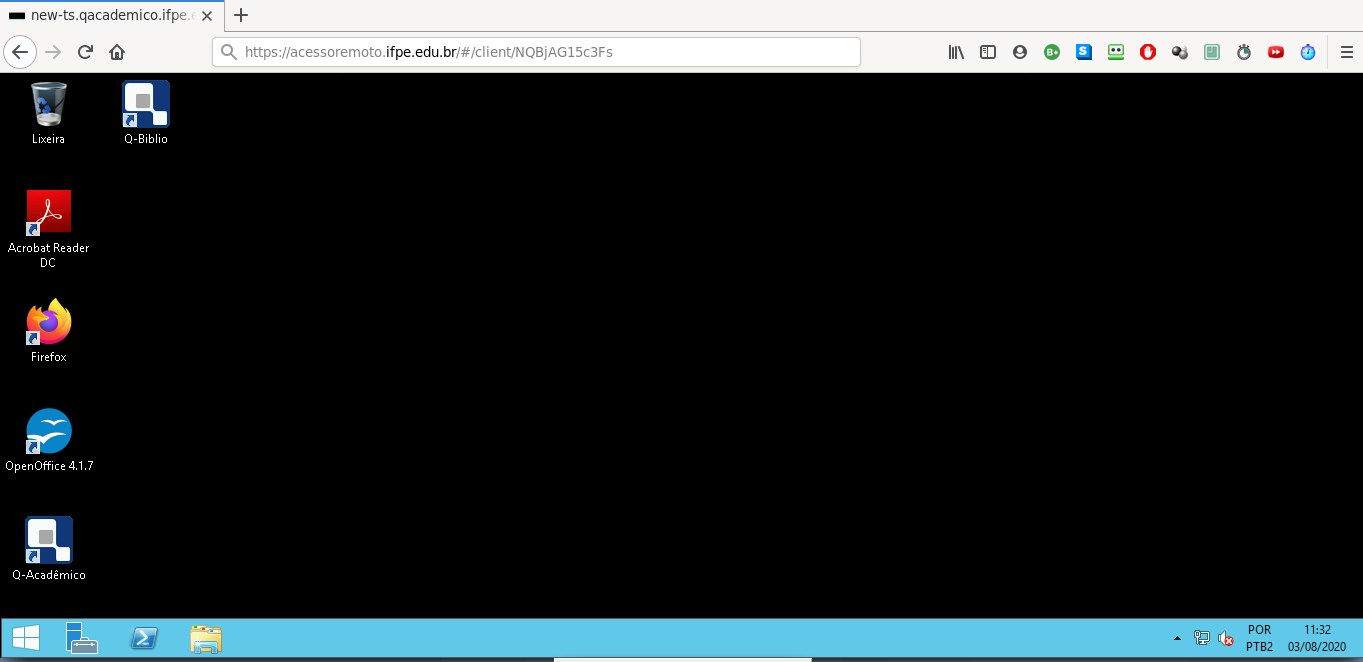
Ao conectar na sessão selecionada, o usuário terá disponível os aplicativos do Q-acadêmico e Q-Biblio e poderá acessá-los desde que tenha as credenciais para os respectivos sistemas.
2. Encerrando o acesso ao sistema
Para terminar uma sessão, o usuário deverá clicar no simbolo do Windows, no canto inferior esquerdo.
E , depois, no botão power off, ao lado do nome do usuário.

Depois de clicar no botão power off, clique em desconectar e, depois, na janela que abrir, clique em principal.
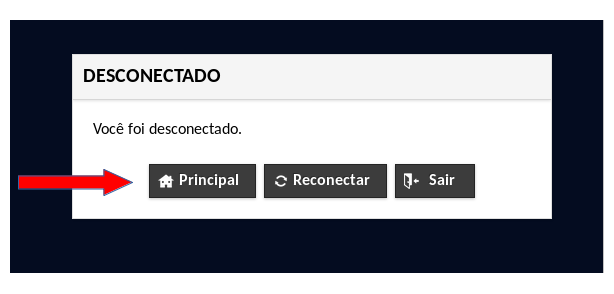
Após sair da sessão, para encerrar o acesso é necessário clicar no CPF do usuário, que fica no canto superior direito, e, depois, em sair.

Depois disso, seu acesso foi totalmente encerrado.
3. Transferência de arquivos para a máquina remota
Após acessar o ambiente remoto, pressione as teclas CTRL+Alt+Shift para abrir o "Shared Drive"
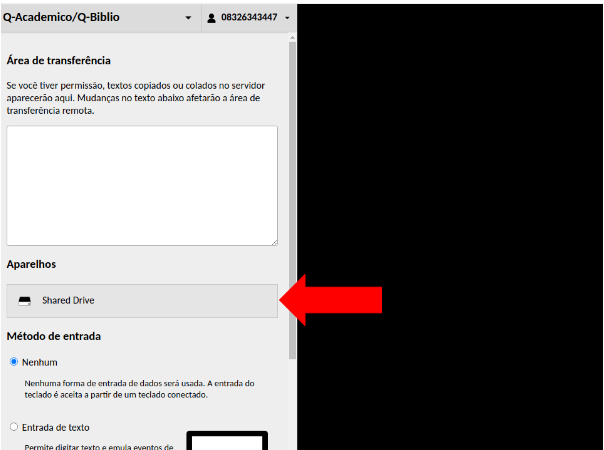
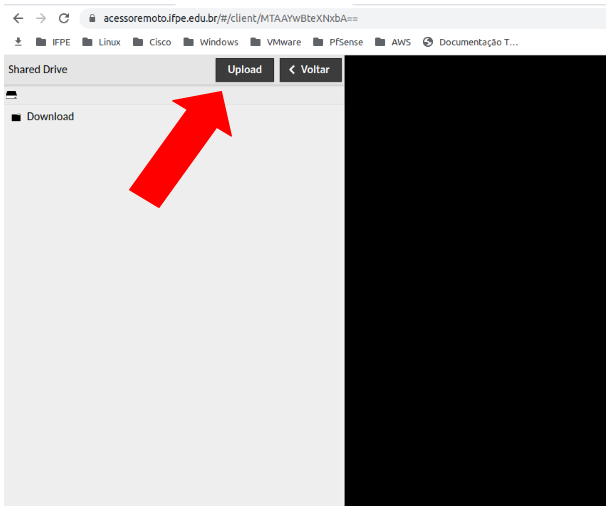
Depois que clicar no "Upload Files" clique no arquivo que deseja transferir e em seguida "Abrir"
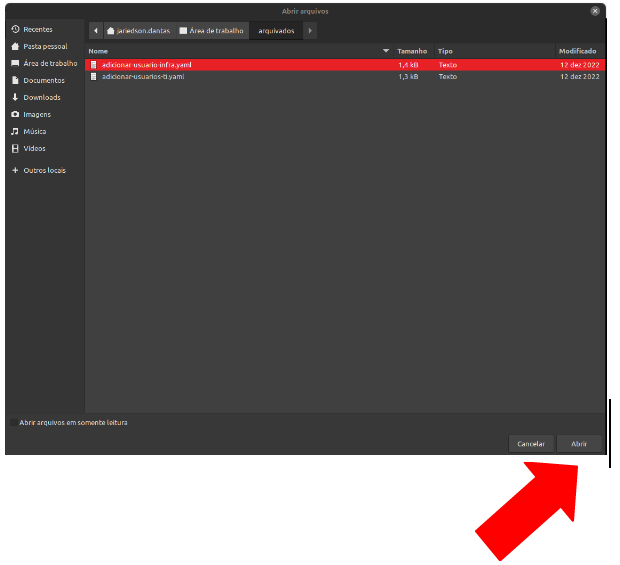
É possível adicionar diversos arquivos ao mesmo tempo
Para sair da tela do "Shared Driver" pressione novamente as teclas "Crtl+Alt+Shift"
Para acessar os arquivos transferidos, vá até "Meu Computador" e acesse a unidade que tem seu usuário do acesso.ifpe, no caso o seu CPF
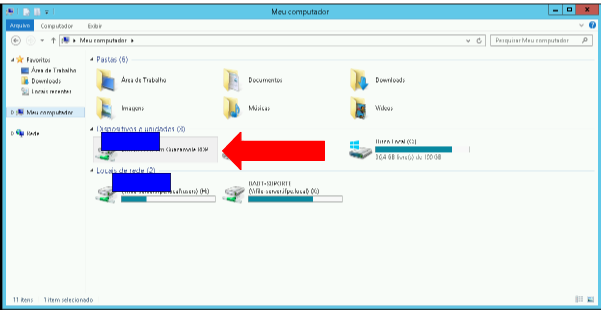
4. Transferindo arquivos da máquina remota
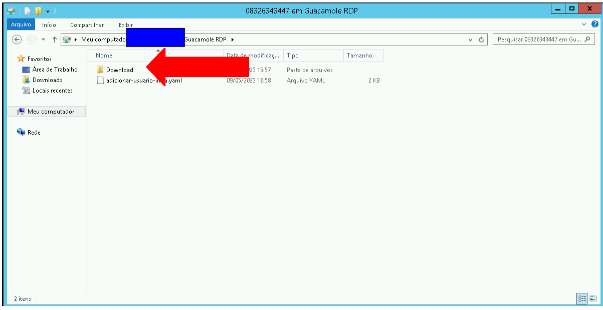
Para transferir arquivos da máquina remota para a máquina local, o usuário deverá, dentro da pasta com seu usuário do acesso.ifpe, colocar os arquivos que queira baixar para a máquina local dentro da pasta download, assim que adicionar os arquivos nesta pasta eles serão baixados para a máquina local.
Armazenamento
Config. ISCSI com multipath no Debian 10
1. Introdução
iSCSI é um dos padrões para armazenamento de dados em rede. Utilizado para conexão entre dispositivos como storages, servidores, computadores e outras estações de trabalho. Neste protocolo, os comandos SCSI são transportados sobre a rede IP.
Multipath usa componentes redundantes - adaptadores, cabos e comutadores - para criar caminhos lógicos entre o servidor e o dispositivo de armazenamento. Se houver uma falha de componente, fazendo com que um caminho lógico falha, a lógica de vários caminhos usará um caminho alternativo de E/S para que os aplicativos ainda possam acessar seus dados. Eventualmente pode melhorar o desempenho ao rebalancear novamente a carga em todos esses caminhos
2. Ferramentas utilizadas
Os softwares utilizados na produção deste tutorial é apresentado a seguir:
- Debian 10, 64 bits
- open-iscsi 2.0.874-7.1
- multipath-tools 0.7.9
3. Configurando o serviço
Todos os comandos executados nesse tutorial foram executados com o usuário root.
3.1. Instalação dos pacotes
apt install multipath-tools multipath-tools-boot3.2. Descobrir os targets
iscsiadm -m discovery -t sendtargets -p 192.168.50.2 # O IP indicado aqui é de uma das interfaces do storage| 192.168.50.2:3260,1 iqn.2017-10.com.hpe:storage.msa2052.15088aa10e 192.168.50.3:3260,2 iqn.2017-10.com.hpe:storage.msa2052.15088aa10e 192.168.51.2:3260,3 iqn.2017-10.com.hpe:storage.msa2052.15088aa10e 192.168.51.3:3260,4 iqn.2017-10.com.hpe:storage.msa2052.15088aa10e |
3.3. Realizar a conexão ao target
iscsiadm -m node --login| Logging in to [iface: default, target: iqn.2017-10.com.hpe:storage.msa2052.15088aa10e, portal: 192.168.50.2,3260] (multiple) Logging in to [iface: default, target: iqn.2017-10.com.hpe:storage.msa2052.15088aa10e, portal: 192.168.51.3,3260] (multiple) Logging in to [iface: default, target: iqn.2017-10.com.hpe:storage.msa2052.15088aa10e, portal: 192.168.51.2,3260] (multiple) Logging in to [iface: default, target: iqn.2017-10.com.hpe:storage.msa2052.15088aa10e, portal: 192.168.50.3,3260] (multiple) Login to [iface: default, target: iqn.2017-10.com.hpe:storage.msa2052.15088aa10e, portal: 192.168.50.2,3260] successful. Login to [iface: default, target: iqn.2017-10.com.hpe:storage.msa2052.15088aa10e, portal: 192.168.51.3,3260] successful. Login to [iface: default, target: iqn.2017-10.com.hpe:storage.msa2052.15088aa10e, portal: 192.168.51.2,3260] successful. Login to [iface: default, target: iqn.2017-10.com.hpe:storage.msa2052.15088aa10e, portal: 192.168.50.3,3260] successful. |
3.4. Listar as sessões ativas
iscsiadm -m session -o show| tcp: [1] 192.168.50.2:3260,1 iqn.2017-10.com.hpe:storage.msa2052.15088aa10e (non-flash) tcp: [2] 192.168.51.3:3260,4 iqn.2017-10.com.hpe:storage.msa2052.15088aa10e (non-flash) tcp: [3] 192.168.51.2:3260,3 iqn.2017-10.com.hpe:storage.msa2052.15088aa10e (non-flash) tcp: [4] 192.168.50.3:3260,2 iqn.2017-10.com.hpe:storage.msa2052.15088aa10e (non-flash) |
3.5. Exibe informações dos dispositivos
multipath -v3|
... ... Saída omitida ... |
3.6. Adicionar o WWID do disco compartilhado via iSCSI para a configuração
multipath -a 360080e50002c8d920000146c5d1bca10| wwid '360080e50002c8d920000146c5d1bca10' added |
3.7. Associar o WWID a um nome, para facilitar o gerenciamento
nano /etc/multipath.conf # Abrir o arquivo| /etc/multipath.conf |
|
# Adicionar este trecho ao final do arquivo multipaths { |
3.8. Reiniciar o serviço para aplicar as alterações
systemctl restart multipathd3.9. Verificar se o dispositivo multipath foi criado
multipath -l| meusdados (360080e50002c8d920000146c5d1bca10) dm-0 HPE,MSA 2052 SAN size=128G features='3 queue_if_no_path queue_mode mq' hwhandler='1 alua' wp=rw |-+- policy='service-time 0' prio=0 status=active | |- 3:0:0:0 sdg 8:32 active undef running | `- 6:0:0:0 sdf 8:16 active undef running `-+- policy='service-time 0' prio=0 status=enabled |- 4:0:0:0 sde 8:0 active undef running `- 7:0:0:0 sdh 8:48 active undef running |
3.10. Configurar a conexão aos dispositivos via iSCSI no boot
sed 's/node.startup = manual/node.startup = automatic/' -i /etc/iscsi/iscsid.conf
sed 's/node.startup = manual/node.startup = automatic/' -i /etc/iscsi/nodes/*/*/default
sed 's/node.conn\[0\].startup = manual/node.conn\[0\].startup = automatic/' -i /etc/iscsi/nodes/*/*/default
Referências
https://openwares.net/2019/07/03/debian-buster-multipath-configuration/
https://docs.microsoft.com/pt-br/azure/storsimple/storsimple-8000-configure-mpio-windows-server
Backup
Documentações relativas a procedimentos de backup e restauração.
Backup do pfSense
Introdução
Este documento destina-se a demonstração dos procedimentos de implementaçao do backup das configurações de um servidor pfSense. A efetivação destes procedimentos permite rápida restauração de um servidor pfSense com problemas ou implantação de um servidor baseado nas configurações de um anterior.
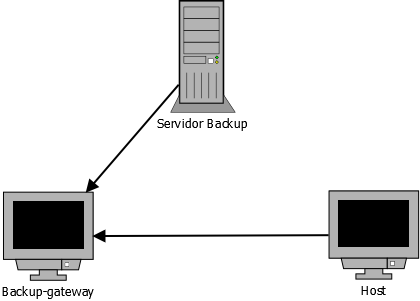
O backup é realizado conforme a figura acima. Este método de backup é utilizado quando não é possível instalar um cliente diretamente no host que sofrerá o backup dos dados. Neste caso, um host intermediário (Backup-gateway), este com capacidade de sofrer backup dos dados, realiza a cópia do pfSense para o seu disco local. Em seguida, de acordo com o agendamento, o servidor de backup realiza o backup dos dados copiados no host intermediário.
Este método é baseado em uma ferramenta open source que realiza a cópia dos dados do pfSense de forma otimizada via comunicação HTTPS. A ferramenta conecta-se ao pfSense com as credenciais e em seguida realiza o download das configurações do pfSense.
Backup do pfSense
A máquina Backup-gateway tem um S.O do tipo centOs versão 7.3.1611. A partir desta máquina e com um usuário com permissões de administrador:
$ sudo yum check-updates
$ sudo yum install epel-release
$ sudo yum install python-pip
$ sudo pip install BeautifulSoup4Agora realize o download do código python a ser utilizado. Coloque este código em /root, por exemplo.:
$ sudo wget -c https://raw.githubusercontent.com/edgauthier/pfsense-backup/master/pfsense-backup.py
$ sudo cp pfsense-backup.py /root/pfsense-backup.pyA utilização do código é da seguinte forma:
Usage: pfsense-backup.py OPTIONS
OPTIONS:
-h | --help
-s <server url> | --server <server url>
The base URL for the pfSense installation.
Example: https://pfsense.example.com
-t <seconds> | --timeout <seconds>
Timeout for network requests.
-u <username> | --username <username>
-p <password> | --password <password>
-d | --directory <directory>
Defaults to current directory.
-r | --rrd
Includes RRD data with the backup.
-f | --file <file>
Defaults to 'pfsense-backup.xml'Um exemplo de uso é o seguinte::
$ ./pfsense-backup.py -s https://172.20.254.100:443 -t 5 -u admin -p senha123 -r -f arquivo_backup_pfSense.xml
Para uso em rotinas, fica a sugestão do seguinte script:
#!/bin/bash
data=$(/bin/date +%Y-%m-%d)
hora=$(/bin/date +%X)
DIR=/backup/pfsense/
host1="PFsense"
user1=admin
passwd1=senha123
server1=172.20.254.100
FILE1=backup_"$host1"-$data.xml
method=https
port=443
timeout=5
logFile=/var/log/backup-pfSense.log
# Funcao
writeLog(){
echo -e "$data $hora - $1\n" >> $logFile
}
backup(){
/root/pfsense-backup.py -s $method://$1:$port -t $timeout -u $2 -p "$3" -r -f "$4"
}
check(){
if [ -e $1 ]; then
writeLog "Cópia de $2 realizada com sucesso!"
else
writeLog "Cópia de $2 não realizada, verificar log."
fi
}
writeLog "Iniciando rotina de cópia dos dados"
mkdir -p $DIR
cd $DIR
backup $server1 $user1 $passwd1 $FILE1
writeLog "Realizando a cópia remota dos dados do host: $host1"
check $FILE1 $host1
writeLog "Encerrando rotina..."Referências
https://github.com/edgauthier/pfsense-backup
Backup do Samba 4
Introdução
Este documento visa a orientação para a configuração de backup dos dados de configurações do Samba4. Porém, não é uma solução para backup dos arquivos dos usuários, servidor de arquivos e etc. A efetivação destes procedimentos permite rápida restauração de um servidor samba com problemas ou implantação de um servidor novo baseado nas configurações restauradas de um anterior.
São utilizados scripts para a realização do backup e baseados em documentação oficial. A versão do samba que funciona corretamente com estes scripts é o Samba v4.0-v4.8. Para versões acima, existe outra abordagem oficial. Estes scripts podem funcionar no próprio host do samba que deve possuir um cliente de backup. Caso não seja possível instalar o cliente de backup, o script pode funcionar normalmente, mas após a geração dos arquivos de saída, estes devem ser enviados a um host intermediário que sofrerá o backup por meio de um cliente válido. Este segundo esquema pode ser representado pela seguinte figura:
Host seria o servidor samba4. O backup-gateway é o host intermediário que recebe os dados gerados pelo script de backup do samba e possui um cliente de backup válido. O servidor de backup é o Bacula, Bareos ou outro servidor desejado.
Backup do samba4
Preparação
Primeiro, tenha um usuário com permissões de administrador e crie um diretório no qual serão armazenados os arquivos gerados para backup. No caso, será utilizado o diretório /root/backup/samba.
$ sudo mkdir /root/backup/samba -p
Realize o download do tarball do samba contendo o script de backup fornecido pelos desenvolvedores.
$ cd /usr/src
$ sudo wget http://ftp.samba.org/pub/samba/samba-latest.tar.gz
$ sudo tar -xvzf samba-latest.tar.gzEncontre o script em questão:
$ find / -iname samba_backup
Deverá aparecer uma saída apontando esta localização. Onde "x.x" é a especificação da versão do samba no seu cenário:
/usr/src/samba-4.x.x/source4/scripting/bin/samba_backup
Copiar para um local adequado, exemplo: /root/scripts/:
$ sudo cp /usr/src/samba-4.8.4/source4/scripting/bin/samba_backup /root/scripts/
A partir daqui preste bastante atenção. Será necessário alterar variáveis no script original e posteriormente inserir um trecho de código se for o seu caso. Caso seu samba4 seja compilado, realize da seguinte maneira:
$ sudo nano /root/scripts/samba_backup
DIRS="private etc sysvol"
FROMWHERE=/usr/local/samba
WHERE=/root/backup/sambaCaso o seu samba4 seja instalado via pacotes de repositórios:
$ sydi nano /root/scripts/samba_backup
DIRS="private /etc/samba sysvol"
FROMWHERE=/var/lib/samba
WHERE=/root/backup/sambaAgora insira (cole) o seguinte trecho de código na linha 85 se o seu samba4 foi instalado via repositório de pacotes:
elif [ "$d" = "/etc/samba" ]; then
# Run the backup.
# --warning=no-file-ignored set to suppress "socket ignored" messages.
tar cjf ${WHERE}/${n}.${WHEN}.tar.bz2 $d --warning=no-file-ignored
Status=$? # Preserve $? for message, since [ alters it.
if [ $Status -ne 0 ]; then
echo "Error while archiving ${WHERE}/${n}.${WHEN}.tar.bz2 - status = $Status"
exit 1
fiEste código é necessário pois sem ele uma parte dos arquivos não seria copiada.
Ajuste permissões:
$ sudo chmod 750 /root/backup/samba/
$ sudo chown root:root /root/scripts/samba_backupExecução
Antes de rodar o script é NECESSÁRIO parar o serviço do samba. Então, faça da seguinte maneira:
$ sudo service samba stop
$ /root/scripts/samba_backup 2>/dev/nullOs arquivos ficarão em /root/backup/samba/:
$ ls root/backup/samba/
_etc_samba.2018-08-20.tar.bz2
samba4_private.2018-08-20.tar.bz2
sysvol.2018-08-20.tar.bz2Rotina de backup
Sugere-se a adição deste script à rotina do host para uma execução periódica. Porém, é importante alterar o script para que seja possível parar o samba antes de executar o script! Pode ser inserido tal código ao script:
# PARAR SAMBA, INÍCIO DO SCRIPT:
/etc/init.d/samba stop
......
# INICIAR SAMBA APÓS TODA A EXECUÇÃO DO SCRIPT, NAS ULTIMAS LINHAS:
# START SAMBA
/etc/init.d/samba startRestaurando os arquivos
Por se tratar de procedimento complexo em que o sucesso depende muito das variáveis envolvidas no ambiente, não é possível garantir o sucesso dos métodos de restauração à seguir para qualquer caso. Assim, o administrador deve realizar os devidos ajustes para conseguir ter sucesso na operação.
Observações importantes:
- Nunca tente restaurar e realizar uma troca de versão do samba ao mesmo tempo. Sempre restaure, tenha um sistema funcional, e depois realize a atualização;
- Não troque o hostname nem o endereço de IP para não ter problemas com o kerberos e DNS;
- RECOMENDADO: restaure na mesma instância de S.O que estava executando o serviço anteriormente.
- Se for necessário reinstalar o sistema, será necessário que primeiro seja instalado corretamente o seu active directory controller.
Pare o samba!
$ sudo /etc/init.d/samba stopRemova os diretórios anteriores caso samba4 seja compilado:
$ sudo rm -rf /usr/local/samba/etc
$ sudo rm -rf /usr/local/samba/private
$ sudo rm -rf /usr/local/samba/var/locks/sysvolApague os diretórios anteriores caso samba4 seja instalado via repositório de pacotes:
$ sudo rm -rf /etc/samba/
$ sudo rm -rf /var/lib/samba/sysvol/
$ sudo rm -rf /var/lib/samba/private/O arquivo compactado por vezes vai gerar uma estrutura de diretórios partindo da raiz "/", assim, ao copiar do backup para a pasta real, copie somente a parte do caminho que resta. Por exemplo, no caso de /etc/samba/ copie o diretório, dentro do arquivo compactado relativo ao etc, a partir do que estiver dentro de "samba", ou seja:
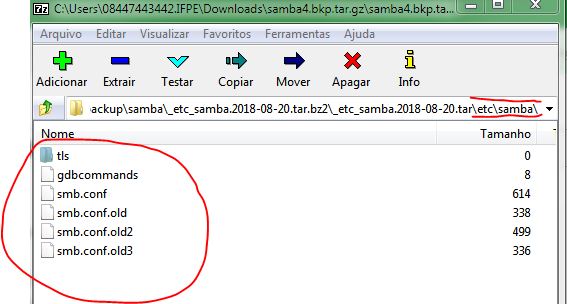
Estes arquivos devem ser copiados para /etc/samba/.
Assim, copie para os caminhos reais os conteúdos dos arquivos do "etc" (_etc_samba.Timestamp.tar.bz2), "private"(samba4_private.Timestamp.tar.bz2) e "sysvol"(sysvol.Timestamp.tar.bz2). Os caminhos reais, como apontado anteriormente, dependem da instalação do seu samba, se compilada ou não. Timestamp é um data no formato AAAA-MM-DD, Ex: 2018-08-24.
Supondo que esteja no diretório que contém os três arquivos do backup:
$ sudo tar -jxf etc.{Timestamp}.tar.bz2 -C /CAMINHO/COMPILADO/OU/NÃO
$ sudo tar -jxf samba4_private.{Timestamp}.tar.bz2 -C /CAMINHO/COMPILADO/OU/NÃO
$ sudo tar -jxf sysvol.{Timestamp}.tar.bz2 -C /CAMINHO/COMPILADO/OU/NÃORenomeie os arquivos *.ldp.bak para *.ldb:
$ find /LOCAL/DO/PRIVATE -type f -name '*.ldb.bak' -print0 | while read -d $'\0' f ; do mv "$f" "${f%.bak}" ; doneSe o backup não contém ACLs extendidas, execute:
$ sudo samba-tool ntacl sysvolresetSe você utiliza o samba como backend DNS, execute o comando à seguir para consertar os hardlinks das bases DNS:
$ sudo samba_upgradedns --dns-backend=BIND9_DLZEntão pode reiniciar o serviço do samba e realizar os devidos ajustes.
$ sudo /etc/init.d/samba startReferências
https://wiki.samba.org/index.php/Using_the_samba_backup_script
https://wiki.samba.org/index.php/Back_up_and_Restoring_a_Samba_AD_DC
Solução de backup: Bareos
Introdução
![]()
Este documento destina-se a demonstração dos procedimentos de instalação e configuração básica da solução de backup Bareos. Tal solução permite a realização de trabalhos de backup e restauração de dados. São suportadas máquinas clientes Linux e Windows.
As máquinas servidoras suportadas são do tipo Linux Debian, RedHat e Suse, porém, NESTE MANUAL será apresentada a instalação em sistemas CentOs na versão >=7. A versão contemplada do Bareos é a 17.2.
O Bareos é dividido em três componentes principais: o Director, o Console, o Storage Daemon e o File Daemon. O Director é o componente central, atuando como controlador que contata clientes e salva dados de backups nos armazenamentos. O Console é um componente utilizado para acessar configurações, verificar status e fazer alterações nos parâmetros do servidor via linha de comando. O Storage Daemon é o armazenamento dos dados de backup e é independente do Director pois nem sempre o mesmo servidor que controla é o mesmo que armazena os backups diretamente. E finalmente, o File Daemon é o componente cliente, aquele que recebe conexões do Director e provê a este os arquivos de backup referente aos conjuntos de arquivos configurados. Abaixo uma ilustração de como se dá a comunicação entre os componentes:
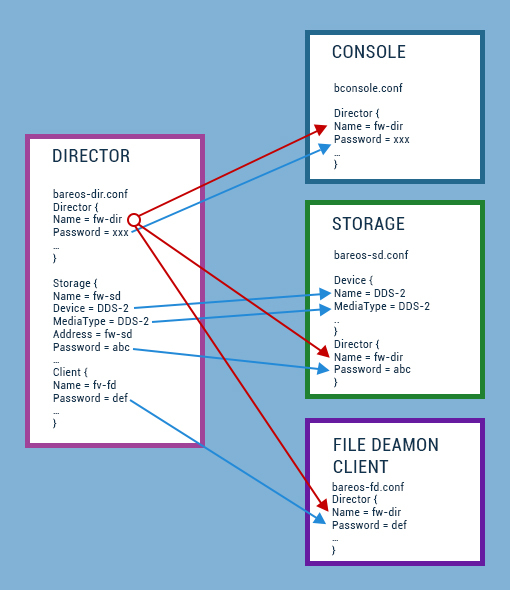
É possível notar que alguns nomes e senhas devem ser as mesmas em diferentes componentes do sistema de backup. Isto ocorre pois, o mesmo atributo tem parâmetros diferentes à depender do contexto. Por exemplo, o atributo Director, no contexto do Director, tem a função de definir as principais configurações neste componente. Já no cliente, o atributo Director informa qual é o Director que pode acessá-lo e a senha autorizada. IMPORTANTE notar estas diferenças.
A primeira seção do documento é a de instalação do servidor da solução e o painel de gerenciamento web. A segunda seção é a de configuração do servidor e da solução de gerência web. A terceira sessão é a instalação e adição do cliente na lista do servidor. A quarta sessão demonstra como criar um trabalho de backup. Por fim, a última seção apresenta como realizar restauração de backupsa anteriores.
Instalação
Para instalar a solução será necessário primeiro instalar um tipo de banco de dados para uso próprio, em seguida instalar a solução em si, posteriormente instalar o bareos-webui e realizar algumas configurações básicas do servidor e de rede.
Instalando o PostgreSQL
Neste manual será demonstrada a instalação do PostgreSQL (recomendado) para a solução de backup Bareos. Será instalada a versão 10 do banco de dados PostgreSQL.
Primeiro, com um usuário com poderes de superusuário, adicione o repositório da versão 10 do banco a seu S.O da família Red Hat:
$ sudo yum -y install https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7-x86_64/pgdg-centos10-10-2.noarch.rpm
Em seguida, instale os pacotes necessários ao PostgreSQL:
$ sudo yum -y install postgresql10 postgresql10-devel postgresql10-contrib postgresql10-libs postgresql10-test postgresql10-server postgresql10-docs
Ative o serviço do PostgreSQL:
$ sudo systemctl enable postgresql-10
Rode o comando para inicializar a base de dados:
$ sudo /usr/pgsql-10/bin/postgresql-10-setup initdb
Inicie o serviço e verifque o statatus:
$ sudo service postgresql-10 start$ sudo service postgresql-10 status
Altere o parâmetro de conexões máximas no arquivo de configuração do PostgreSQL:
$ sudo nano /var/lib/pgsql/10/data/postgresql.conf
max_connections = 256Reinicie o postgresql:
$ sudo service postgresql-10 restart
Ativando o FirewallD
O FirewallD é um firewall disponível no CentOs. Ele é utilizado na demonstração deste manual para filtrar portas na interface de produção do servidor de backup. Ative e inicie o FirewallD:
$ sudo systemctl enable firewalld
$ sudo service firewalld start
$ sudo service firewalld status
firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: active (running) since Qua 2018-09-12 15:19:34 EDT; 41min ago
Docs: man:firewalld(1)
Main PID: 731 (firewalld)
CGroup: /system.slice/firewalld.service
└─731 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid
Set 12 15:19:31 t-bareos systemd[1]: Starting firewalld - dynamic firewall daemon...
Set 12 15:19:34 t-bareos systemd[1]: Started firewalld - dynamic firewall daemon.Ative as portas que futuramente serão necessárias para o Bareos:
$ firewall-cmd --list-all
$ firewall-cmd --add-port=80/tcp --permanent
$ firewall-cmd --add-port=9101/tcp --permanent
$ firewall-cmd --add-port=9102/tcp --permanent
$ firewall-cmd --add-port=9103/tcp --permanent
$ firewall-cmd --reload
$ firewall-cmd --list-allCaso haja mais de uma interface de rede no servidor, uma boa prática é criar "zonas" no FirewallD contemplando as interfaces utilizadas para backup. Em seguida, realizar os filtros de portas nas zonas criadas ao invés de fazê-lo em todas as interfaces.
Instalando o Bareos
Considerando o S.O centOs na versão >=7 e o Bareos na versão 17.2, defina algumas variáveis para facilitar o processo de instalação:
$ DIST=CentOS_7
$ RELEASE=release/17.2/
$ URL=http://download.bareos.org/bareos/$RELEASE/$DIST Faça o download do arquivo que adiciona o repositório do Bareos a seu S.O:
$ sudo wget -O /etc/yum.repos.d/bareos.repo $URL/bareos.repo
Agora execute o comando para realizar a instalação dos pacotes do Bareos:
$ sudo yum install -y bareos bareos-database-postgresql
Adicione o usuário postgres ao grupo do bareos, isto será necessário nas próximas etapas.
$ sudo usermod -aG bareos postgres
Execute os seguintes comandos para realizar o login com o usuário postgres e criar as tabelas do banco de dados da solução de backup:
$ sudo su - postgres
$ /usr/lib/bareos/scripts/create_bareos_database
$ /usr/lib/bareos/scripts/make_bareos_tables
$ /usr/lib/bareos/scripts/grant_bareos_privileges
$ exitApós este ponto o servidor Bareos já estará instalado, mas a configuração da ferramenta será apresentada nas seções seguintes.
Instalando o bareos-webui
O bareos-webui é uma interface de gerenciamento web para o Bareos. Similiar ao webacula para o Bacula.
O bareos-webui é muito útil para emitir comandos e ver configurações do servidor de backup. Entretanto, para modificar as configurações é necessário utilizar as ferramentas convencionais: bconsole e edição dos arquivos de configuração em texto.
A instalação é simples, basta apenas executar o seguinte comando:
$ sudo yum install -y bareos-webui
Configuração
Bareos
Configure o arquivo principal do Director (componente central do Bareos). Sugere-se alterar parâmetros para os descritos abaixos como segue:
$ sudo nano /etc/bareos/bareos-dir.d/director/bareos-dir.conf
Name = #NOME DO SEU DIRECTOR: EX.: ifpe-cafg-bkp1
Maximum Concurrent Jobs = 256
Heartbeat Interval = 1 Minute
FD Connect Timeout = 180sNeste ponto, com a alteração do nome do Director no arquivo principal, É NECESSÁRIO alterar o nome do Director nos arquivos de configuração do File Daemon (cliente de backup que o servidor possui) e do Storage (componente que armazena os backups).
$ sudo nano /etc/bareos/bareos-fd.d/director/bareos-dir.conf
Name = #NOME DO SEU DIRECTOR
$ sudo nano /etc/bareos/bareos-sd.d/director/bareos-dir.conf
Name = #NOME DO SEU DIRECTORPara este manual, o diretório de backup considerado será o /backup. Serão criados subdiretórios para armazenamento dos backups dos tipos COMPLETO, INCREMENTAL e DIFERENCIAL.
$ sudo mkdir -p /backup/COMPLETO
$ sudo mkdir -p /backup/INCREMENTAL
$ sudo mkdir -p /backup/DIFERENCIALAltere as permissões dos referidos diretórios:
$ sudo chown -R bareos:bareos /backup/
$ sudo chmod -R 700 /backup/Inicie e ative os daemons do Bareos:
$ sudo systemctl enable bareos-dir
$ sudo service bareos-dir start
$ sudo service bareos-sd start
$ sudo service bareos-fd startStorage daemons e Devices
Estes dois atributos são configurações globais que já possuem definições padrão no momento da instalação, entretanto, para uma boa prática no que se refere à configuração do servidor de backup Bareos, devem ser definidas logo no início antes de configurados qualquer trabalhos de backup.
Device é o dispositivo no qual volumes serão armazenados. No Linux, aponta basicamente para um caminho dentro da estrutura de diretórios do S.O. Como deve ser de seu conhecimento, um caminho pode apontar para um diretório físico na partição do S.O, para um diretório NFS remoto, para uma partição separada, para um disco completo separado, para um storage, e etc.
Storage refere-se a um grupo de armazenamento que dentre outras configurações, irá conter um ou mais Devices como atributos configurados. Vejamos à seguir uma configuração de exemplo para os Devices e os Storage Daemons.
Abaixo, as configurações recomendadas do atributo Device no contexto do Storage. O arquivo configurado é o /etc/bareos/bareos-sd.d/device/FileStorage.conf.
$ sudo nano /etc/bareos/bareos-sd.d/device/FileStorage.conf
...
Device {
Name = Completo-Dev01
Media Type = File
Archive Device = /backup/COMPLETO
LabelMedia = yes
Random Access = yes
AutomaticMount = yes
RemovableMedia = no
AlwaysOpen = no
Maximum Concurrent Jobs = 64
}
Device {
Name = Incremental-Dev01
Media Type = File
Archive Device = /backup/INCREMENTAL
LabelMedia = yes
Random Access = yes
AutomaticMount = yes
RemovableMedia = no
AlwaysOpen = no
Maximum Concurrent Jobs = 64
}
Device {
Name = Diferencial-Dev01
Media Type = File
Archive Device = /backup/DIFERENCIAL
LabelMedia = yes
Random Access = yes
AutomaticMount = yes
RemovableMedia = no
AlwaysOpen = no
Maximum Concurrent Jobs = 64
}Note que há um atributo Device para cada tipo de backup: completo, incremental e diferencial. Este mapeamento é interessante em um cenário futuro onde o armazenamento dos backups Full, por exemplo, seja separado (até fisicamente) dos outros tipos de backup. Essa melhoria não acarretaria em alterações no Bareos, apenas no S.O - fstab. OBS: não há configuração de Device no contexto do Director.
A configuração do atributo Storage é feita por meio do arquivo /etc/bareos/bareos-sd.d/storage/bareos-sd.conf. Ele contém configurações globais do armazenamento em seu próprio contexto.
Abaixo, as configurações recomendadas do atributo Storage no contexto do Director. O arquivo configurado é o /etc/bareos/bareos-dir.d/storage/File.conf.
$ sudo nano /etc/bareos/bareos-dir.d/storage/File.conf
...
Storage {
Name = Completo-Dev01
Address = # IP DO STORAGE, geralmente o mesmo IP desta máquina servidora
SDPort = 9103
Password = # senha em /etc/bareos/bareos-sd.d/director/bareos-dir.conf
Device = Completo-Dev01
Media Type = File
Maximum Concurrent Jobs = 64
}
Storage {
Name = Diferencial-Dev01
Address = # IP DO STORAGE, geralmente o mesmo IP desta máquina servidora
SDPort = 9103
Password = # senha em /etc/bareos/bareos-sd.d/director/bareos-dir.conf
Device = Diferencial-Dev01
Media Type = File
Maximum Concurrent Jobs = 64
}
Storage {
Name = Incremental-Dev01
Address = # IP DO STORAGE, geralmente o mesmo IP desta máquina servidora
SDPort = 9103
Password = # senha em /etc/bareos/bareos-sd.d/director/bareos-dir.conf
Device = Incremental-Dev01
Media Type = File
Maximum Concurrent Jobs = 64
}O atributo Address é o IP ou FQDN do servidor onde está configurado o SD do Bareos.
O atributo SDPort informa a porta de acesso que está liberada no Storage (em seu próprio contexto).
O atributo Password informa a senha de acesso ao Storage.
O atributo Device informa qual dispositivo configurado no Storage será utilizado. Neste caso, um mesmo Storage pode ter vários Devices, porém, é optado neste manual pela atribução de um único Device a um único Storage.
O Media Type é o tipo de mídia selecionada, por padrão é "File".
Maximum Concurrent Jobs é o número máximo de trabalhos sendo executados simultaneamente que podem escrever em no referido Storage.
Findo tais configurações, somente se faz necessário apontar os nomes dos Storages como parâmetro nos atributos que o solicitarem ou que este for obrigatório (pools, Jobs...).
Reinicie o Storage:
$ sudo service bareos-sd restartBareos-webui
No arquivo /etc/bareos-webui/configuration.ini há configurações que podem ser modificadas à vontade do administrador. Por padrão não há esta necessidade.
Ao final do arquivo /etc/bareos/bareos-dir.d/profile/webui-admin.conf, adicione as seguintes linhas antes da chave de fechamento do atributo Profile:
$ sudo nano /etc/bareos/bareos-dir.d/profile/webui-admin.conf
Profile {
....
Plugin Options ACL = *all*
}Configure o arquivo /etc/bareos-webui/directors.ini alterando principalmente as linhas 10 e 16 como segue:
$ sudo nano /etc/bareos-webui/directors.ini
....
[ifpe-cafg-bkp1] #linha 10
...
diraddress = # IP ou nome da máquina que contém o bareos (geralmente "localhost") #linha 16
Crie um usuário que possa usar a interface web. Basta copiar o original e modificá-lo:
$ sudo cp /etc/bareos/bareos-dir.d/console/admin.conf.example /etc/bareos/bareos-dir.d/console/cgti.conf
$ sudo nano /etc/bareos/bareos-dir.d/console/cgti.conf
Console {
Name = cgti
Password = "cgti"
Profile = "webui-admin"
} Como root, execute o seguinte comando:
$ sudo setsebool -P httpd_can_network_connect on
Agora reinicie o apache (httpd) e o bareos:
$ sudo service httpd stop
$ sudo service httpd start
$ sudo service bareos-director stop
$ sudo service bareos-director startAcesse a página de login do bareos-webui:
http://IP_SERVIDOR/bareos-webui/

Utilizando as credenciais anteriormente configuradas é possível obter acesso a página inicial.
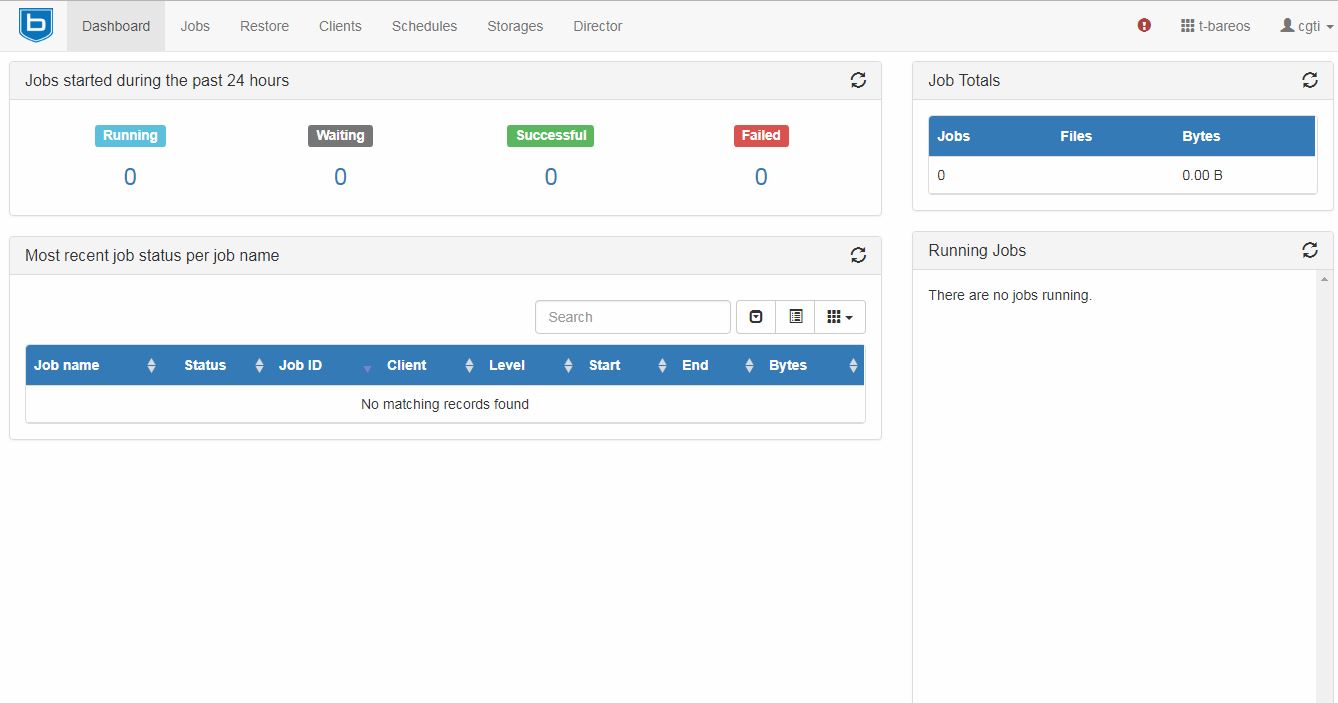
Inicialmente não haverão muitas informações pois ainda não há trabalhos de backup configurados, apenas trabalhos automáticos de backup de arquivos da própria ferramenta configurados inicialmente às 21h00 .
Instalação do cliente de backup
Etapa obrigatória no servidor
Antes de qualquer operação, primeiro verifique se o servidor possui conectividade com o cliente na interface de rede desejada. $ ping #ip_do_cliente
Cientes da conexão, NO SERVIDOR, digite o comando bconsole e em seguida, dentro do bconsole, rode o seguinte comando:
* configure add client name=#nome_do_cliente address=#ip_do_cliente password=#senha
Exported resource file "/etc/bareos/bareos-dir-export/client/ifpe-cafg-sambafs-fd/bareos-fd.d/director/t-bareos.conf":
Director {
Name = t-bareos
Password = "[md5]9af9de4b43cfd0d9d4e196fcced09bfd"
}
Created resource config file "/etc/bareos/bareos-dir.d/client/ifpe-cafg-sambafs-fd.conf":
Client {
Name = ifpe-cafg-sambafs-fd
Address = 10.20.253.199
Password = cgti
}
*Este comando realiza duas operações: cria os arquivos de configuração necessários no servidor e cria um arquivo de configuração do servidor a ser enviado e utilizado no cliente. Este arquivo já contém o nome do Director e a senha informada no comando. Guarde este arquivo para momento posterior.
#nome_do_cliente geralmente é o hostname do host adicionado do sufixo "-fd". No caso de exemplo, o nome do cliente foi ifpe-cafg-sambafs-fd.
#ip_do_cliente é o IP do cliente na interface a qual se deseja realizar trabalhos de backup. 10.20.253.199 no caso em questão.
#senha é a senha a qual o Director precisará para ter acesso ao Cliente bareos-fd. É uma senha de autorização ao Director. Mas como dito, esta já é enviada pré-configurada para o cliente.
A configuração no servidor está completa, agora é necessário realizar as configurações do cliente.
Para o nosso exemplo, agora copie via SCP, FTP, rsync, para a máquina cliente, o arquivo de configuração que está no caminho /etc/bareos/bareos-dir-export/client/ifpe-cafg-sambafs-fd/bareos-fd.d/director/t-bareos.conf.
As próximas etapas são no host cliente.
Clientes Linux
O cliente de backup Linux funciona para várias distribuições e versões, no entanto, a versão do cliente NUNCA deve ser superior a versão do servidor. Ou seja, se o servidor está na versão 17, instalar um cliente versão 18 será um problema, pois a comunicação não é compatível.
No caso do Debian, instale o pacote bareos-filedaemon no cliente:
$ sudo apt install -y bareos-filedaemon
No caso do centOs, rode os seguinte comandos antes da instalação:
$ DIST=CentOS_7
$ RELEASE=release/17.2/
$ URL=http://download.bareos.org/bareos/$RELEASE/$DIST
$ wget -O /etc/yum.repos.d/bareos.repo $URL/bareos.repo Agora, rode o comando de instalação do pacote:
$ sudo yum install -y bareos-filedaemon
Acesse o arquivo de configuração do próprio cliente em /etc/bareos/bareos-fd.d/client/myself.conf
$ sudo nano /etc/bareos/bareos-fd.d/client/myself.conf
Client {
Name = ifpe-cafg-sambafs-fd
Maximum Concurrent Jobs = 20
}A principal informação é o atributo Name que deve estar igual ao que foi configurado no servidor e vice-versa. Recomenda-se a manutenção do atributo.
Agora copie o arquivo gerado no final do processo de adição do cliente no servidor. Suponha que ele esteja em /home/cgti/t-bareos.conf. Copie para /etc/bareos/bareos-fd.d/director/. Isto permitirá a conexão do Director a este cliente via a senha informada na adição do cliente no lado do servidor.
Reinicie o bareos-fd, caso Debian.
$ sudo service bareos-fd restart
Ative e inicie o bareos-fd, caso centOs.
$ sudo systemctl enable bareos-fd
$ sudo systemctl start bareos-fdNO SERVIDOR, rode o comando bconsole. Ao abrir o terminal, digite o comando status client e selecione na lista o cliente por meio da opção numerada, digite-o seguido de ENTER:
* status client
The defined Client resources are:
1: ifpe-cafg-sambafs-fd
2: bareos-fd
Select Client (File daemon) resource (1-2): 1
Connecting to Client ifpe-cafg-sambafs-fd at 10.20.253.199:9102
ifpe-cafg-sambafs-fd Version: 16.2.4 (01 July 2016) x86_64-pc-linux-gnu debian Debian GNU/Linux 9.3 (stretch)
Daemon started 17-set-18 16:27. Jobs: run=0 running=0.
Heap: heap=131,072 smbytes=28,182 max_bytes=28,571 bufs=70 max_bufs=73
Sizeof: boffset_t=8 size_t=8 debug=0 trace=0 bwlimit=0kB/s
Running Jobs:
t-bareos (director) connected at: 17-set-18 18:08
No Jobs running.
====
Terminated Jobs:
JobId Level Files Bytes Status Finished Name
======================================================================
6 Full 10 233.3 M OK 14-set-18 18:56 gab-comunicacoes-job
14 Incr 0 0 OK 17-set-18 11:14 gab-comunicacoes-job
15 Incr 0 0 OK 17-set-18 11:25 gab-comunicacoes-job
====
*O servidor tentará obter conexão com o cliente. Caso haja algum problema, verifique se a porta 9102 - padrão na comunicação servidor-cliente - está aberta em prováveis firewalls de rede ou no firewall local do cliente. Para outros problemas, verificar se o IP está correto, se a máquina cliente está conectada, e verifique logs da ferramenta para soluções em casos mais complexos.
Clientes Windows
Para instalar clientes windows, primeiro realize o download do executável para a instalação de acordo com a versão do Director. Os binários de instalação podem ser encontrados em http://download.bareos.org/bareos/release/latest/windows. O instalador segue o padrão da maioria dos programas para Windows.
Após abrir o instalador, clique em Next e em I Agree, em seguida selecione o diretório de instalação, sugere-se o padrão. Na próxima tela, marque somente a opção File Daemon (client) e Tray Monitor em Interfaces.
Em seguida, prestar bastante atenção aos campos pois devem estar de acordo com o que foi criado no Director nos passos anteriores - lembre-se que o cliente é adicionado ao servidor antes de proceder à sua instalação propriamente dita. Então preencha os campos de acordo com as informações. A senha complexa em Client Monitor Password não precisa ser alterada. Clique Next.
Será mostrado um arquivo em texto para ser adiciona ao servidor, mas lembre-se que este arquivo já está no servidor, então, ignore e clique em Next. Pronto, conclua a instalação e REINICIE O WINDOWS.
NO SERVIDOR, rode o comando bconsole. Ao abrir o terminal, digite o comando status client e selecione na lista o cliente por meio da opção numerada, digite-o seguido de ENTER:
* status client
The defined Client resources are:
1: ifpe-cafg-sambafs-fd
2: bareos-fd
3: ifpe-cafg-maq12-fd
Select Client (File daemon) resource (1-3): 3
Connecting to Client ifpe-cafg-maq12-fd at 10.20.253.112:9102
ifpe-cafg-maq12-fd Version: 17.2.4 (21 Sep 2017) VSS Linux Cross-compile Win64
Daemon started 20-Sep-18 12:22. Jobs: run=0 running=0.
Microsoft Windows 7 Professional Service Pack 1 (build 7601), 64-bit
Heap: heap=0 smbytes=40,477 max_bytes=40,671 bufs=81 max_bufs=83
Sizeof: boffset_t=8 size_t=8 debug=0 trace=1 bwlimit=0kB/s
Running Jobs:
t-win7-aleciano-mon (director) connected at: 20-Sep-18 12:23
t-bareos (director) connected at: 20-Sep-18 14:34
No Jobs running.
====
Terminated Jobs:
====
*O servidor tentará conexão com o cliente. Como podemos ver a conexão teve sucesso, na linha 11 inclusive é possível ver o tipo de S.O, confirmando que é o cliente Windows recém-instalado.
Os binários ficam instalados em C:\Program Files\Bareos. E os arquivos de configuração em C:\ProgramData\Bareos.
Criando o primeiro trabalho de backup
Atributo Job
A configuração dos trabalhos de backup envolvem a definição de parâmetros nos arquivos de configuração que informarão entre outras coisas, o agendamento do backup, em que local será salvo, informações sobre os volumes utilizados e qual o cliente de backup utilizado.
Abaixo os principais atributos na configuração de um Job (trabalho). Serão apresentados cada um destes em detalhes à seguir. O arquivo utilizado é o /etc/bareos/bareos-dir.d/gab-comunicacoes-fd.conf:
$ sudo nano /etc/bareos/bareos-dir.d/gab-comunicacoes-fd.conf
Job {
Name = gab-comunicacoes-job
Type = Backup
Client = ifpe-cafg-sambafs-fd
FileSet = gab-comunicacoes-fileset
Schedule = gab-comunicacoes-schedule
Pool = gab-comunicacoes-completo-pool
Messages = Standard
}Para uma melhor compreensão dos termos no que se refere a ferramenta de backup, consultar referências oficiais da ferramentas que estão linkadas no final deste manual.
Name é o nome do trabalho (job) de backup. Ele define de forma única um determinado trabalho, por este motivo, não devem haver diferentes trabalhos com o mesmo nome.
Type é o tipo do trabalho. Podem haver trabalhos do tipo backup, restore, verify, migrate, dentre outros. Por padrão é utilizado o tipo backup, para realizar cópia dos arquivos. O segundo tipo, restore, é mais utilizado quando se deseja restaurar os arquivos, porém, é comum ter esse trabalho com o tipo restore configurado mas não agendado (sem Schedule), ou seja, só será executado manualmente por intermédio de um administrador do sistema.
Client define o nome do cliente que sofrerá a ação de backup. Este nome é definido no ato de configuração do cliente e na adição do cliente de backup às configurações do servidor Bareos. Não é obrigatório ser o mesmo nome do host cliente, mas uma boa prática é utilizar este parâmetro como nome para que seja possível rapidamente identificar a qual host um cliente de backup está realacionado.
O Fileset ou conjunto de arquivos define quais os diretórios sofrerão ação de backup. Por exemplo, /srv/arquivos/termos/ é um parâmetro utilizado na configuração de um dos atributos de Fileset - este e outros atributos serão detalhados nas seções à seguir..
Schedule é o atributo que determina qual tipo de agendamento configurado será utilizado para realização do trabalho de backup. Por exemplo, por meio do schedule é possível informar que o trabalho será realizado todos os dias às 20:15.
Para compreender o Pool é preciso compreender os volumes. O volume equivale a um arquivo de tamanho ou duração máxima pré-configurado e que vai recebendo os dados salvos nos trabalhos de backup. Quando um volume fica cheio ou tem sua duração encerrada, o Bareos proverá um novo. Assim, essa configuração dos volumes é feita pelo atributo Pool. Cada um destes agrupa uma série de volumes. Portanto, o atibuto Pool define os parâmetros que os volumes criados naquele trabalho irão possuir por padrão - um volume pode ter seu atributo modificado após a criação. Por exemplo: inicialmente um volume pode ter herdado da configuração do Pool o tamanho máximo de 1 GB. Mas é possível alterar esse volume em específico posteriormente e aumentá-lo para 2 GB ou reduzir para 490 MB.
Messages é um atributo que define para onde as mensagens ou "logs" do trabalho serão enviadas em tempo real. Por padrão, são enviadas para Standard, que é a saída padrão do Bareos. Posteriormente é possível acessar um console (bconsole) e ver as mensagens recebidas no "canal" Standard.
Os atributos fileset, pool e schedule podem ser configurados para cada trabalho de backup em específico. Isto é necessário pois, por exemplo, nem todos os arquivos que sofrerão backup estarão no mesmo fileset e nem todos os trabalhos obedecerão ao mesmo schedule. Por isto recomenda-se a sua configuração para cada tipo de trabalho de backup inserido.
Atributo Fileset
O fileset é o conjunto de arquivos para backup. Para configurar filesets, no servidor, insira o arquivo no diretório /etc/bareos/bareos-dir.d/fileset. Abaixo, um exemplo de configuração básica:
$ sudo nano /etc/bareos/bareos-dir.d/fileset/gab-comunicacoes-fileset.conf
FileSet {
Name = gab-comunicacoes-fileset
Description = "Fileset dos arquivos de portarias, resoluções e termos."
Include {
Options {
Signature = MD5
Compression = GZIP6
}
File = /srv/arquivos/portarias
File = /srv/arquivos/resolucoes
File = /srv/arquivos/termos
}
}Atributo Pool
O atributo pool, como dito mencionado, configura os volumes a serem utilizados no trabalho de backup. Abaixo um exemplo de configuração básica. O arquivo localiza-se em /etc/bareos/bareos-dir.d/pool/gab-comunicacoes-pool.conf.
$ sudo nano /etc/bareos/bareos-dir.d/pool/gab-comunicacoes-pool.conf
Pool {
Name = gab-comunicacoes-incremental-pool
Pool Type = Backup
Storage = Incremental-Dev01
Recycle Oldest Volume = yes
Volume Retention = 6 days
Recycle = yes
AutoPrune = yes
LabelFormat = gab-comunicacoes-incr
Maximum Volume Bytes = 5G
}
Pool {
Name = gab-comunicacoes-diferencial-pool
Pool Type = Backup
Storage = Diferencial-Dev01
Recycle Oldest Volume = yes
Volume Retention = 21 days
Recycle = yes
AutoPrune = yes
LabelFormat = gab-comunicacoes-dif
Maximum Volume Bytes = 15G
}
Pool {
Name = gab-comunicacoes-completo-pool
Pool Type = Backup
Storage = Completo-Dev01
Recycle Oldest Volume = yes
Volume Retention = 45 days
Recycle = yes
AutoPrune = yes
LabelFormat = gab-comunicacoes-full
Maximum Volume Bytes = 25G
}Note que foram selecionados um pool diferente para cada tipo de backup. Isto se deve ao fato de que os requisitos para cada tipo de backup podem ser diferentes: tamanho, duração, nome...
O atributo Name define o nome do pool e geralmente este nome é utilizado na configuração do agendamento.
O atributo Pool Type define o tipo de pool utilizado.
O atributo Storage define o Storage utilizado pelo pool em questão.
O atributo LabelFormat define o rótulo do nome dos volumes quando estes forem implementados. Geralmente é adicionado um número respeitando uma sequência ao final do nome do volume.
Volume Retention e Maximum Volume Bytes definem, respectivamente, o tempo desde a sua criação em que o volume continuará sendo escrito, e, o tamanho máximo do volume. Ao se atingir o tempo ou tamanho máximo do volume, na próxima situação em que for solicitada a sua escrita, o Bareos proverá um volume novo.
Os atributos remanescentes podem ser alterados conforme a necessidade do administrador. Para mais informações se faz necessário a consulta na documentação oficial da ferramenta.
Atributo Schedule
Este é responsável pela programação ou agendamento de trabalhos, sejam de backups, restauração (restore) e etc. Ele não é necessário por padrão na configuração do Job, mas em um ambiente em produção este tipo de automatização se faz necessária. Abaixo a configuração de exemplo do Schedule. O arquivo configurado é o /etc/bareos/bareos-dir.d/schedule/gab-comunicacoes-schedule.conf:
$ sudo nano /etc/bareos/bareos-dir.d/schedule/gab-comunicacoes-schedule.conf
Schedule {
Name = gab-comunicacoes-schedule
Run = Level=Full Pool=gab-comunicacoes-completo-pool 1st sun at 00:05
Run = Level=Differential Pool=gab-comunicacoes-diferencial-pool 2nd-5th sun at 00:05
Run = Level=Incremental Pool=gab-comunicacoes-incremental-pool at 20:05
}Note que o atributo Pool configurado anteriormente é utilizado aqui neste ponto. O trabalho de backup que utilizar este agendamento irá executar um trabalho Full às 00:05 do primeiro domingo (do mês), um trabalho Differential do segundo ao quinto domingo do mês (se houver) e um trabalho Incremental todo os dias às 20:05. Para mais exemplos de agendamentos consulte a documentação oficial da ferramenta.
Executando o trabalho
Há várias formas de executar o trabalho. Se ele estiver agendado, será executado automaticamente, mas é possível executar o trabalho de forma manual para verificar se as configurações estão corretas. Será demonstrado via bconsole e via painel web.
Bconsole:
Na linha de comando do servidor digite o comando bconsole, em seguida ative as mensagens automáticas no painel:
$ sudo bconsole
Connecting to Director localhost:9101
1000 OK: t-bareos Version: 17.2.4 (21 Sep 2017)
Enter a period to cancel a command.
* autodisplay on
Digite run e ENTER, em seguida digite o número correspondente ao trabalho dentre as opções apresentadas e ENTER:
*run
Automatically selected Catalog: MyCatalog
Using Catalog "MyCatalog"
A job name must be specified.
The defined Job resources are:
1: RestoreFiles
2: gab-comunicacoes-job
3: BackupCatalog
4: backup-bareos-fd
Select Job resource (1-4): 2Agora digite "yes" e ENTER.
Run Backup job
JobName: gab-comunicacoes-job
Level: Incremental
Client: ifpe-cafg-sambafs-fd
Format: Native
FileSet: gab-comunicacoes-fileset
Pool: gab-comunicacoes-completo-pool (From Job resource)
Storage: Completo-Dev01 (From Pool resource)
When: 2018-09-14 17:03:12
Priority: 10
OK to run? (yes/mod/no): yes
Job queued. JobId=6
You have messages.Pronto, o trabalho foi iniciado. As mensagens aparecerão na tela com várias informações, a mais importante é saber no final se o backup foi de sucesso (OK) ou apresentou erro (Error).
14-Set 17:56 bareos-sd JobId 6: Elapsed time=00:00:19, Transfer rate=12.28 M Bytes/second
14-Set 17:56 t-bareos JobId 6: sql_create.c:872 Insert of attributes batch table done
14-Set 17:56 t-bareos JobId 6: Bareos t-bareos 17.2.4 (21Sep17):
Build OS: x86_64-redhat-linux-gnu redhat CentOS Linux release 7.4.1708 (Core)
JobId: 6
Job: gab-comunicacoes-job.2018-09-14_17.56.07_33
Backup Level: Full (upgraded from Incremental)
Client: "ifpe-cafg-sambafs-fd" 16.2.4 (01Jul16) x86_64-pc-linux-gnu,debian,Debian GNU/Linux 9.3 (stretch)
FileSet: "gab-comunicacoes-fileset" 2018-09-14 17:04:00
Pool: "gab-comunicacoes-completo-pool" (From Job resource)
Catalog: "MyCatalog" (From Client resource)
Storage: "Completo-Dev01" (From Pool resource)
Scheduled time: 14-Set-2018 17:56:06
Start time: 14-Set-2018 17:56:09
End time: 14-Set-2018 17:56:30
Elapsed time: 21 secs
Priority: 10
FD Files Written: 10
SD Files Written: 10
FD Bytes Written: 233,394,285 (233.3 MB)
SD Bytes Written: 233,395,389 (233.3 MB)
Rate: 11114.0 KB/s
Software Compression: 4.2 % (gzip)
VSS: no
Encryption: no
Accurate: no
Volume name(s): gab-comunicacoes-full0003
Volume Session Id: 2
Volume Session Time: 1536962107
Last Volume Bytes: 233,571,320 (233.5 MB)
Non-fatal FD errors: 0
SD Errors: 0
FD termination status: OK
SD termination status: OK
Termination: Backup OKPronto, backup OK. Agora execute o trabalho manualmente via painel web na próxima sessão.
Painel do bareos-webui:
Acesse a página do bareos-webui http://IP_SERVIDOR/bareos-webui e logue com seu usuário e senha. Após isso, na página inicial, clique em Jobs no painel superior lado esquerdo.
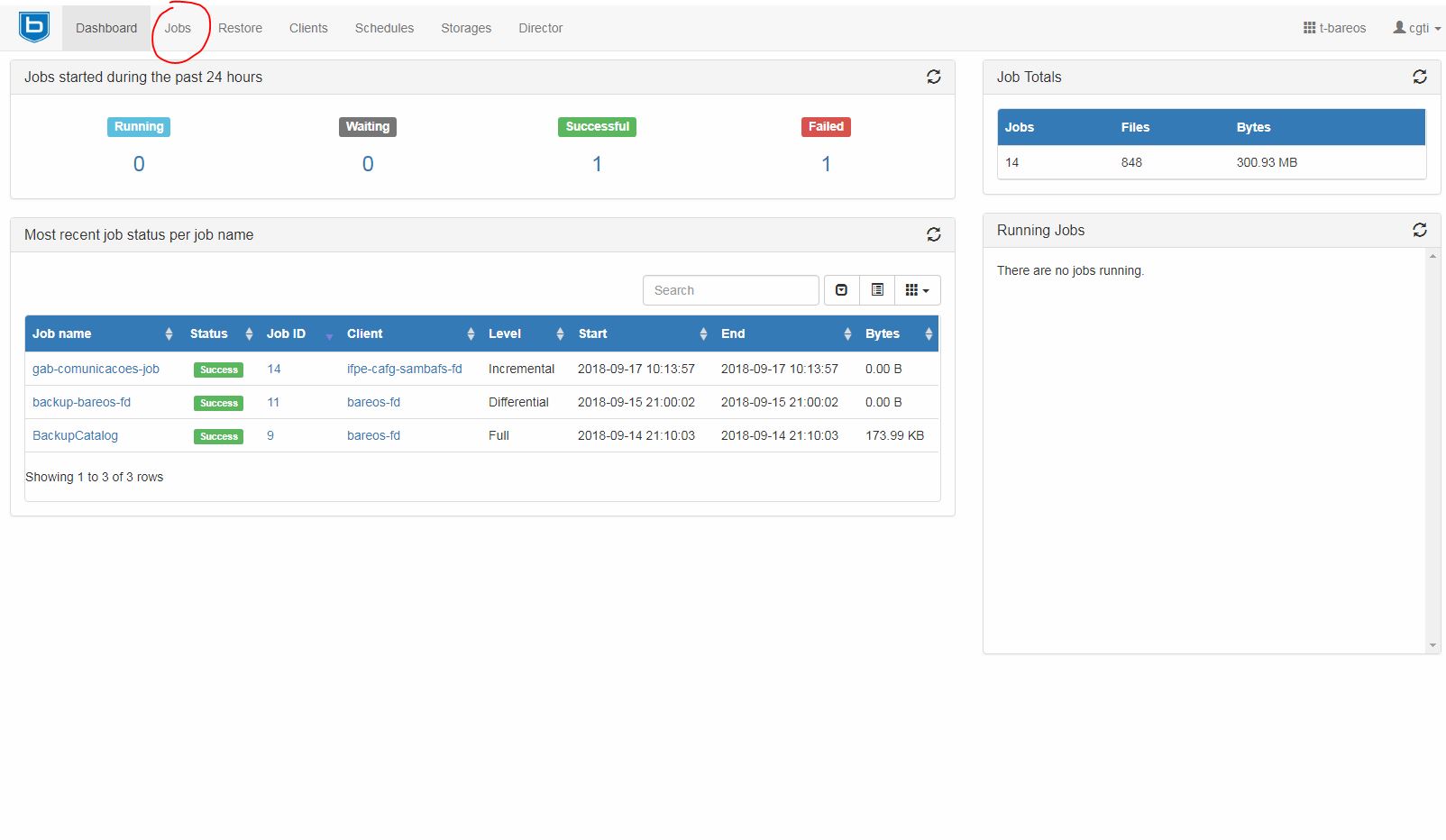
Em seguida clique na segunda aba, de nome Actions. Na página que será exibida, clique no botão de "play" logo ao lado do nome que deseja executar o trabalho de backup.
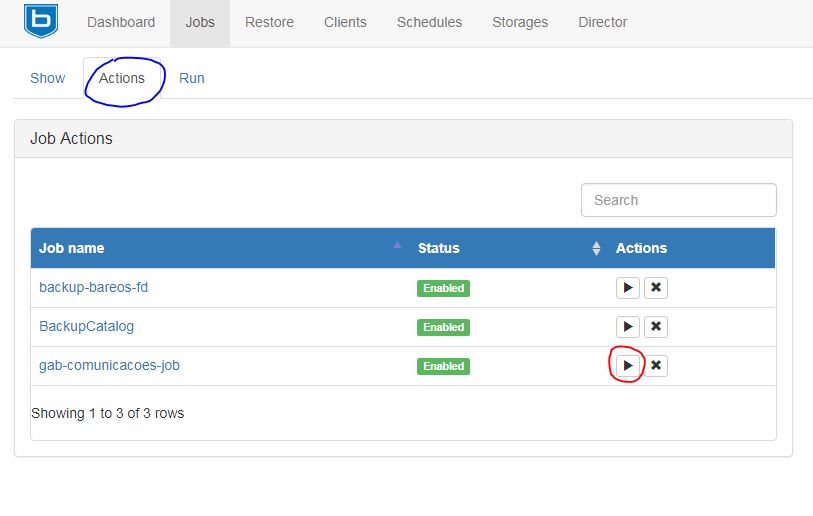
O sistema informará que o trabalho foi agendado e o seu o ID também será apresentado.
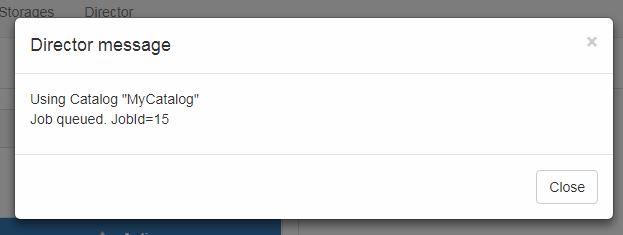
O ID de um job é uma informação importante para identificá-lo perante outros que foram executados ao longo da vida do sistema.
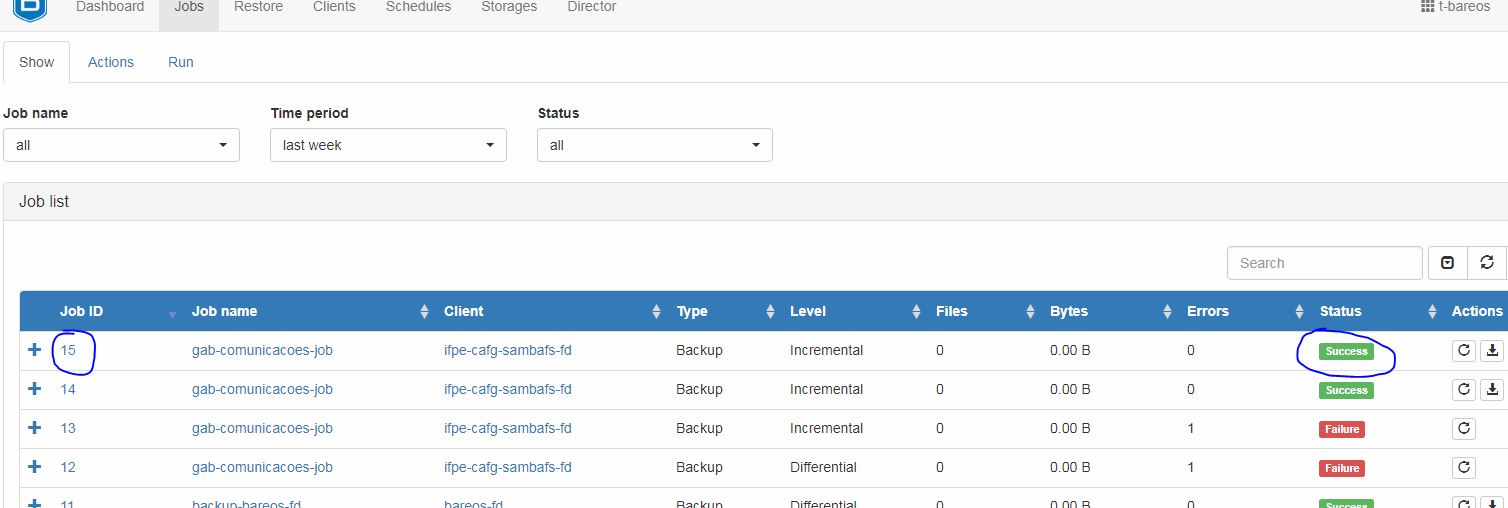
Um tempo depois, dependendo do volume dados, será possível notar qual o resultado do trabalho. Como é possível notar na imagem abaixo, o trabalho de ID=15 foi realizado com sucesso. Assim, este trabalho está configurado corretamente, seu cliente está com conexão disponível e será executado conforme o agendamento (Schedule) determinado.
Realizando um trabalho de restauração de um backup
O trabalho de restauração (restore) tem como objetivo recuperar o backup salvo no servidor e restaurar os arquivos no cliente. Também é possível que este trabalho recupere os arquivos PARA um outro host, por exemplo, quando a máquina cliente não está operacional e se deseja utilizar os arquivos em um host secundário ou reserva. Neste caso, o cliente de backup precisa estar instalado na segunda máquina e configurado no servidor como um dos clientes normais.
Suponha que os arquivos representados pelo fileset gab-comunicacoes-fileset tenham sido apagados acidentalmente no cliente. Vamos utilizar o painel web para realizar a restauração. O fileset em questão aponta para os diretórios: /srv/arquivos/portarias; /srv/arquivos/resolucoes; /srv/arquivos/termos.
Acesse a página do bareos-webui http://IP_SERVIDOR/bareos-webui/ e logue com seu usuário e senha. Após isso, na página inicial, clique em Restore no painel superior lado esquerdo.
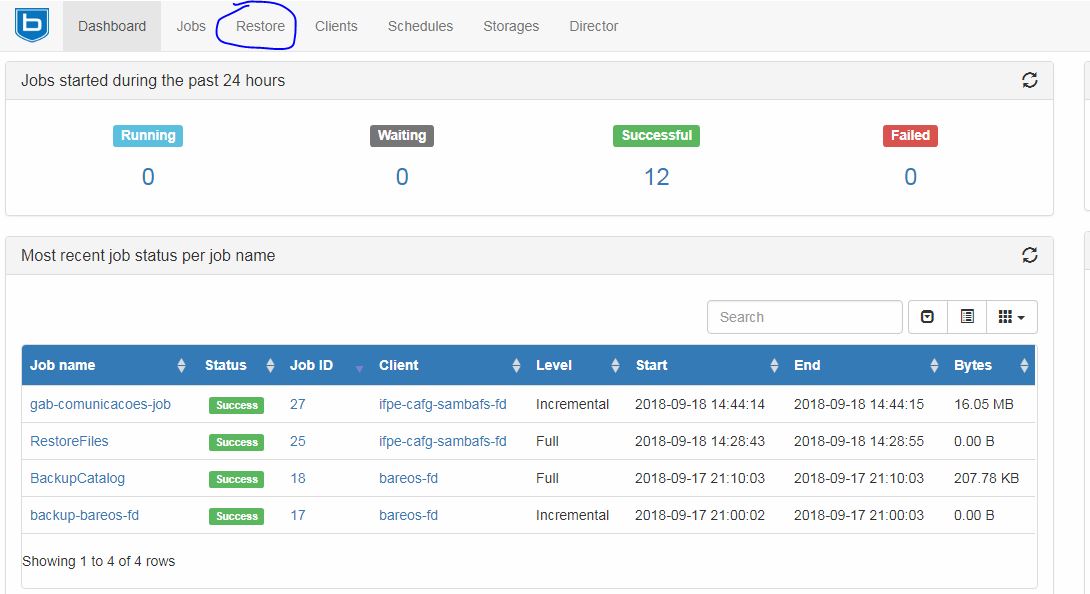
Na próxima tela existem diversas informações sobre como pode ser realizado o trabalho de restauração. No lado esquerdo primeira opção (Client) é possível selecionar o cliente a qual os dados a qual deseja recuperação estão relacionados. A segunda opção (Backup jobs) seleciona a qual trabalho de backup deseja-se a recuperação, geralmente é escolhido o último - qualquer que seja - ou o último Full. A terceira opção (Merge all Client filesets), quando marcada 'Yes'. informa que todos os filesets do cliente serão recuperados, mesmo que no último backup incremental algum deles não tenha sido modificado. A quarta opção (Merge all related...), quando marcada 'Yes', informa que todos os trabalhos de backups até o último Full serão mesclados e recuperados. A quinta opção (Restore to client) pergunta a qual cliente se deseja restaurar os dados, geralmente é ao mesmo cliente de onde se originaram os dados no backup, porém, é possível selecionar um outro cliente. A sexta opção não se altera. A sétima opção (Replace files on client) pergunta se caso existirem os dados ou diretórios na máquina do cliente no caminho da oitava opção, se podem ser sobrescritos. A última opção (Restore location on client), como comentado, é o caminho para o qual os dados serão restaurados. Por padrão, o Bareos seleciona um local temporário ao invés do local original. Após escolher, clicar Restore.
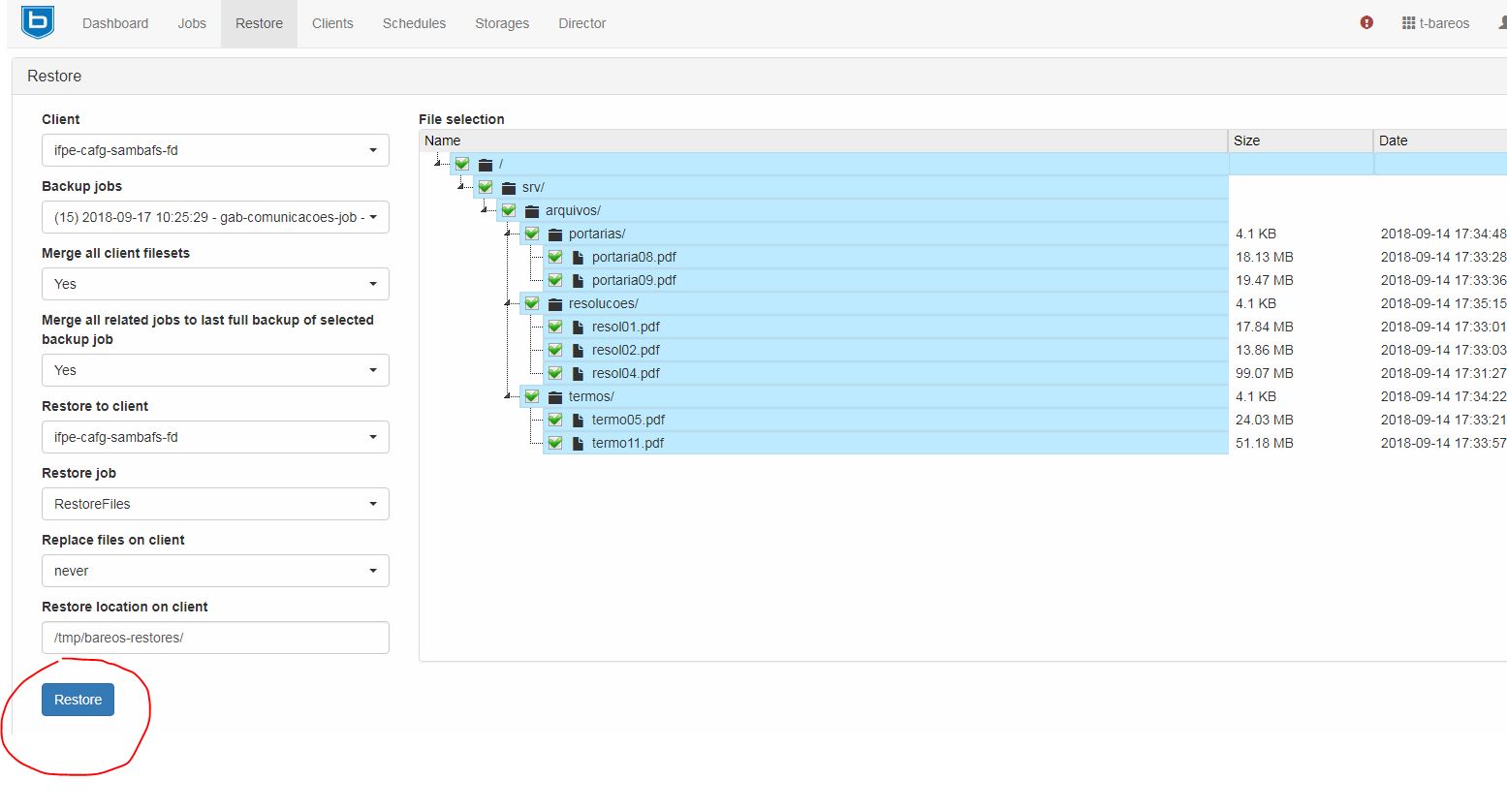
Aparecerá na tela um diálogo informando que o trabalho foi inciado.

Após algum tempo será possível ver na lista de trabalhos do Bareos no painel web o resultado do trabalho. Então, é possível o administrador mover os dados do diretório temporário para onde necessitar.

Referências
Referência principal do Bareos, http://doc.bareos.org/master/html/bareos-manual-main-reference.html
Certificados SSL
Instalar certificados do ICPEdu
1. Introdução
A Infraestrutura de Chaves Públicas para Ensino e Pesquisa (AC ICPEdu) é o serviço de certificação digital oferecido pela RNP, que provê infraestrutura pronta para a emissão de certificados digitais e chaves de segurança.
A modalidade adotada pelo IFPE é a “Certificado Corporativo”, onde as instituições clientes emitem gratuitamente certificados digitais qualificados pela GlobalSign, uma das maiores autoridades certificadoras do mundo. Isso fortalece a confiança dos usuários, que têm a garantia de estar fazendo negócios com uma instituição idônea.
Este documento visa a orientar a configuração do certificado emitido através do Sistema de Chamados do IFPE nos servidores web Apache e NGinx.
Observe que todos os passos são obrigatórios.
2. Utilizando os arquivos
Neste ponto devemos ter os seguintes arquivos disponíveis:
- dh-4096.pem
Arquivo contém os parâmetros Diffie-Hellman usado para fortalecer o canal criptografado e dificultar ataques que interceptam o tráfego criptografado.
- icpedu-chain.crt
Arquivo contém a cadeia de autoridades de certificação que inclui a CA do ICPEdu e as da Globalsign, usado para permitir que o cliente confira a validade dos certificados.
- globalsign-ca.crt
Arquivo contém o certificado da CA raiz da Globalsign, usado para permitir que o cliente confira a validade dos certificados.
- CEPO171124239914-chain.crt
Arquivo inclui a cadeia de certificados que inclui o do ICPEdu, os da Globalsign, e o certificado gerado para o dispositivo final ou aplicação. É ele que será apresentado aos navegadores dos usuários.
- CEPO171124239914.key
Arquivo inclui a chave privada do certificado gerado para o dispositivo final ou aplicação. Ele será usada para compor o fluxo criptografado, juntamente com o certificado, aos navegadores dos usuários.
A seguir estão instruções de como utilizar os arquivos gerados nos servidores HTTP Apache e NGinx, instalados nos sistemas operacionais Linux Debian (os comandos são também válidos para Ubuntu) e Centos.
2.1. O diretório dos arquivos
Para seguir os passos definidos neste documento, copie os arquivos para o diretório “/etc/ssl/private/”.
[usuario@linux /tmp]$ sudo mkdir -p /etc/ssl/private
[usuario@linux /tmp]$ sudo cp *.crt *.key *.pem *.pfx /etc/ssl/privateOs passos a seguir não funcionarão se os arquivos não estiverem no diretório “/etc/ssl/private/”.
2.2. Configuração com Apache
Por padrão, os arquivos de configuração dos sites do Apache no Debian e Ubuntu ficam localizados em “/etc/apache2/sites-available/" . Caso esteja instalado no Centos, ficam em “/etc/httpd/conf.d”
No arquivo de cada host, dentro da sessão “<VirtualHost>” onde o SSL esteja habilitado inclua as definições de modo que se pareça com o que é mostrado a seguir:
Para identificar qual VirtualHost possui SSL habilitado, observe se uma linha com o conteúdo "SSLEngine On" existe
Caso a versão do apache seja inferior a 2.3.6
<VirtualHost <server_name>:443>
Listen 443
SSLEngine on
ServerName <server_name>:443
...
# Certificados
SSLCertificateFile /etc/ssl/private/CEPO171124239914-chain.crt
SSLCACertificateFile /etc/ssl/private/globalsign-ca.crt
SSLCertificateKeyFile /etc/ssl/private/CEPO171124239914.key
SSLCertificateChainFile /etc/ssl/private/icpedu-chain.crt
...
</VirtualHost> Caso a versão do apache seja superior a 2.3.6 e inferior a 2.4.8
<VirtualHost <server_name>:443>
Listen 443
SSLEngine on
ServerName <server_name>:443
...
# OCSP Stappling
SSLUseStapling On
SSLStaplingCache "shmcb:/tmp/stapling-cache(150000)"
# Certificados
SSLCertificateFile /etc/ssl/private/CEPO171124239914-chain.crt
SSLCACertificateFile /etc/ssl/private/globalsign-ca.crt
SSLCertificateKeyFile /etc/ssl/private/CEPO171124239914.key
SSLCertificateChainFile /etc/ssl/private/icpedu-chain.crt
...
</VirtualHost> Caso a versão do apache seja a 2.4.8 ou superior
No arquivo de cada host, dentro da sessão “<VirtualHost>” onde o SSL esteja habilitado inclua as definições (da linha 6 até a 14) de modo que se pareça com o que é mostrado a seguir:
<VirtualHost <server_name>:443>
Listen 443
SSLEngine on
ServerName <server_name>:443
...
# OCSP Stappling
SSLUseStapling On
SSLStaplingCache "shmcb:/tmp/stapling-cache(150000)"
# Certificados
SSLOpenSSLConfCmd DHParameters /etc/ssl/private/dh-4096.pem
SSLCACertificateFile /etc/ssl/private/globalsign-ca.crt
SSLCertificateFile /etc/ssl/private/CEPO171124239914-chain.crt
SSLCertificateKeyFile /etc/ssl/private/CEPO171124239914.key
...
</VirtualHost>Após realizar a configuração mostrada é preciso aplicar as alterações.
Procure por erros de configuração:[usuario@linux ~]$ sudo apache2ctl -t
Se tudo correu bem, reinicie o serviço (no Debian/Ubuntu/Centos):[usuario@linux ~]$ sudo apache2ctl -k restart
Para que as alterações entrem em vigor é necessário reiniciar o serviço
2.3. Configuração com NGinx
Utilize o comando nginx -v para saber a versão do nginx atualmente instalada. Para este documento, é necessário que versão seja igual ou superior a 1.3.7.
Por padrão, os arquivos de configuração dos sites do NGinx no Debian e Ubuntu ficam localizados em “/etc/nginx/sites-available/" . Caso esteja instalado no Centos, ficam em “/etc/nginx/conf.d”
No arquivo de cada host, na sessão “server” onde o SSL esteja habilitado inclua as definições (da linha 4 até a 13) de modo que se pareça com o que é mostrado a seguir:
Para identificar qual VirtualHost possui SSL habilitado, observe se uma linha com o conteúdo "listen 443 ssl" existe
server {
listen 443 ssl;
...
# OCSP Stappling
ssl_stapling on;
ssl_stapling_verify on;
resolver 208.67.220.220 208.67.222.222 valid=600s;
# Certificados
ssl_dhparam /etc/ssl/private/dh-4096.pem;
ssl_certificate /etc/ssl/private/CEPO171124239914-chain.crt;
ssl_certificate_key /etc/ssl/private/CEPO171124239914.key;
ssl_trusted_certificate /etc/ssl/private/icpedu-chain.crt;
...
}Após realizar a configuração mostrada é preciso aplicar as alterações.
Procure por erros de configuração:[usuario@linux ~]$ sudo nginx -t
Se tudo correu bem, reinicie o serviço (no Debian/Ubuntu e Centos):[usuario@linux ~]$ sudo nginx -s reload
Para que as alterações entrem em vigor é necessário reiniciar o serviço
2.4 Outros sistemas
Caso haja a necessidade de instalar o certificado em outros oftwares (como MS IIS, MS Exchange e CPanel), acesse a documentação de instalação disponibilizada pela Globalsign clicando neste link.
Monitoramento
Capítulo destinado a receber conteúdos relativos ao monitoramento de ativos de rede.
Dell OpenManage: Instalação no Centos 7
1. Introdução
O Dell EMC OpenManage Server Administrator (OMSA) oferece uma solução de gerenciamento de sistemas abrangente e individualizada de duas formas:
- De uma interface gráfica do usuário (GUI) integrada e baseada em navegador da Web
- Por meio de uma interface de linha de comando (CLI) no sistema operacional (SO)
O Server Administrator foi criado para que os administradores de sistema pudessem focar no gerenciamento de toda a rede, sem deixar de fornecer gerenciamento de sistemas individualizado de forma local e remota.
2. Ferramentas utilizadas
Os softwares utilizados na produção deste tutorial é apresentado a seguir:
- CentOS 7.4.1708
- Dell OpenManage 7.4.1-1341
- Dell PowerEdge R710, com iDRAC6
O ambiente utilizado é apresentado a seguir:
-
Servidor físico, modelo Dell R710, com o sistema operacional CentOS 7.4
3. Instalando o OMSA
Todos os comandos executados nesse tutorial foram executados com o usuário root.
Passos preparatórios
3.1. Instale as dependências do OMSA:
yum install libcmpiCppImpl0 openwsman-server openwsman-client sblim-sfcb pciutils
3.2. Altere os dados do sistema para que ele seja identificado como um RHEL 7, não CentOS:
mv /etc/redhat-release /etc/redhat-release.bak; echo "Red Hat Enterprise Linux Server release 7.0 (Maipo)" >> /etc/redhat-release3.3. Faça download do OMSA para RHEL 7:
wget -c http://downloads.dell.com/FOLDER02645266M/1/OM-SrvAdmin-Dell-Web-LX-7.4.1-1341.RHEL7.x86_64_A00.tar.gz
tar zxvf OM-SrvAdmin-Dell-Web-LX-7.4.1-1341.RHEL7.x86_64_A00.tar.gz
./setup.sh
rm /etc/redhat-release; mv /etc/redhat-release.bak /etc/redhat-release
Crie o arquivo /tmp/CheckSystemType.patch com o conteúdo a seguir. Atente para a formatação na hora da cópia.
--- CheckSystemType 2019-03-22 19:06:17.956718131 -0300
+++ CheckSystemType.new 2019-03-22 19:06:35.053476939 -0300
@@ -204,8 +204,15 @@
IsInSupportedSystemIDs && return $SUPPORTED_DELL_SERVER
- if [ -f /etc/redhat-release ] && [ `grep -c "Maipo" /etc/redhat-release` -gt 0 ]; then
- IsSystemSupportedForRHEL7 && return $SUPPORTED_DELL_SERVER
+ if [ -f /etc/os-release ]; then
+ . /etc/os-release
+ case $VERSION_ID in
+ 7*)
+ case "$ID $ID_LIKE" in
+ *rhel*)
+ IsSystemSupportedForRHEL7 && return $SUPPORTED_DELL_SERVER
+ esac
+ esac
fi
IsClientSystem && return $CLIENT_SYSTEM3.7. Aplique o patch necessário ao funcionamento do OMSA no CentOS:
patch /opt/dell/srvadmin/sbin/CheckSystemType < /tmp/CheckSystemType.patch
Finalizando as coisas
3.8. Configure a iniciação do serviço do OMSA após o boot :
systemctl enable dataeng.service dsm_om_shrsvc.service
3.9. Permita o acesso a porta da interface web do OMSA:
firewall-cmd --zone=public --permanent --add-port=1311/tcp
firewall-cmd --reload
Feita a configuração, utilize o navegador para acessar o enderenço IP do servidor, na porta 1311.
Referencias
OMSA on CentOS 7 (https://www.dell.com/community/Systems-Management-General/OMSA-on-CentOs-7/td-p/4553216)
Dell R720 OpenManage (https://www.centos.org/forums/viewtopic.php?f=49&t=48532)
templates-e-scripts
1. Introdução
Zabbix é uma solução de código aberto para monitoramento de dispositivos e aplicações, sendo capaz de monitorar parâmetros utilizando agentes em diversas plataformas de sistemas operacionais, além de protocolos como SNMP, IPMI, JMX, entre outros.
Este documento destina-se a servir de ponto central para o código dos scripts.
2. Bareos/Bacula
2.1 Bacula/Bareos - Cliente
2.1.1. Atual
Link do template: Última versão do template do cliente
Data: 22-10-2019
Changelog:
- Solucionado erro durante a importação
2.1.2. Anteriores
Link: 20191014 | Data: 14-10-2019 | Changelog: Adicionados comentários aos itens.
2.2. Bacula/Bareos - Storage
2.2.1. Atual
Link do template: Última versão do template do storage
Data: 22-10-2019
Changelog:
- Solucionado erro durante a importação
2.2.2. Anteriores
Link: 20191014 | Data: 14-10-2019 | Changelog: Adicionados comentários aos itens.
2.3. Bacula/Bareos - Director
2.3.1. Atual
Link do template: Última versão do template do director
Links complementares: parâmetro de usuário | script de monitoramento | script de descoberta
Data: 22-10-2019
Changelog:
- Solucionado erro durante a importação
- Removida expressão regular não utilizada
2.3.1. Anteriores
Link: 20191014 | Data: 14-10-2019 | Changelog: Adicionados comentários aos itens; Pequenas melhorias no código dos scripts.
Zabbix: Importando templates
1. Introdução
Zabbix é uma solução de código aberto para monitoramento de dispositivos e aplicações, sendo capaz de monitorar parâmetros utilizando agentes em diversas plataformas de sistemas operacionais, além de protocolos como SNMP, IPMI, JMX, entre outros.
Este documento visa orientar a importação de templates no servidor Zabbix. Ele contém os parâmetros utilizados pelo servidor para monitorar ativos e reportar sua disponibilidade.
2. Ferramentas utilizadas
Este tutorial descreve a instalação do agente no sistema operacional Windows e, apesar da edição utilizada ter sido o Windows 7, pode ter seus passos utilizados para instalar o agente no Windows Server 2008 e 2012, Windows 8/8.1 e Windows 10. Também é abordada a questão de edição posterior à instalação e o controle do processo do agente.
Os softwares utilizados na produção deste tutorial é apresentado a seguir:
- Zabbix Server 3.2.3
3. Importando o template
Estes procedimentos devem ser realizados na interface web do servidor, usando um usuário com permissões suficientes.
3.1. Acesse a interface web
3.2.1. Nela, clique em "Configuração", depois "Templates" e então "Importar"

3.2.2. Na tela que surge, em "Importar arquivo", clique em "Escolher arquivo".

Abrirá um repositório semelhante a imagem abaixo.

3.2.3. Escolha o arquivo do template (com extensão .xml) e clique em "Abrir". (Neste exemplo escolhi o template referente ao ICMP ping).
O nome do mesmo será mostrado no campo “importar arquivo” na interface do zabbix, de acordo com a imagem abaixo.

3.2.4. Na mesma página, logo abaixo, clique em "Importar".

Após concluída a operação aparecerá a seguinte mensagem de acordo com a imagem abaixo.

Repita os passos anteriores para cada template a ser importado.
Zabbix: Instalando o agente em clientes linux
1. Introdução
Zabbix é uma solução de código aberto para monitoramento de dispositivos e aplicações, sendo capaz de monitorar parâmetros utilizando agentes em diversas plataformas de sistemas operacionais, além de protocolos como SNMP, IPMI, JMX, entre outros.
Este documento visa a orientação para a instalação do agente do Zabbix. Ele é utilizado pelo servidor para monitorar ativos e reportar sua disponibilidade permitindo uma visão proativa do parque tecnológico.
2. Ferramentas utilizadas
Este tutorial descreve a instalação do agente no sistema operacional Linux, nas distribuições Debian 8, Ubuntu 14.04 LTS e CentOS 7. Também é abordada a questão de edição posterior à instalação e o controle do processo do agente.
Os softwares utilizados na produção deste tutorial é apresentado a seguir:
- CentOS 7.3
- Debian 8
- Ubuntu 14.04
- Zabbix Agent 3.2.7
3. Configurando o serviço
Estes procedimentos devem ser realizados na máquina a ser monitorada, usando um usuário com permissões administrativas.
Configure o repositório
Para obter a versão mais atual do software, adicione o repositório oficial do Zabbix:
- No Centos
URL='https://repo.zabbix.com/zabbix/3.4/rhel/7/x86_64/zabbix-release-3.4-2.el7.noarch.rpm'
rpm -ivh "$URL" # Adiciona o repositório do zabbix- No Debian
URL='http://repo.zabbix.com/zabbix/3.2/debian/pool/main/z/zabbix-release/zabbix-release_3.2-1+jessie_all.deb'
wget "$URL"
dpkg -i zabbix-release_3.2-1+jessie_all.deb
apt-get update- No Ubuntu
URL='http://repo.zabbix.com/zabbix/3.2/ubuntu/pool/main/z/zabbix-release/zabbix-release_3.2-1+xenial_all.deb'
wget "$URL"
sudo dpkg -i zabbix-release_3.2-1+xenial_all.deb
sudo apt updateInstale o agente
Uma vez que o sistema já esteja usando o repositório do Zabbix, execute a instalação do agente.
- No Centos
yum install zabbix-agent zabbix-get # Instala o agente do zabbix
systemctl enable zabbix-agent # Configura o systemd para iniciar o agente do zabbix após o boot- No Debian
apt-get install zabbix-agent zabbix-get # Instala o agente do zabbix
systemctl enable zabbix-agent # Configura o systemd para iniciar o agente do zabbix após o boot- No Ubuntu
apt-get install zabbix-agent zabbix-get # Instala o agente do zabbix
systemctl enable zabbix-agent # Configura o systemd para iniciar o agente do zabbix após o bootConfigure o firewall
Configure o firewall para permitir a conexão entre o servidor e o agente
- No Centos
firewall-cmd --permanent --add-port=10051/tcp # configura o firewalld para permitir conexões ao proxy do zabbix
firewall-cmd --permanent --add-port=10050/tcp # configura o firewalld para permitir conexões ao agente do zabbix
firewall-cmd --reload- No Debian
Não há firewall ativado por padrão.
- No Ubuntu
Não há firewall ativado por padrão.
Configure o agente
Preencha as informações requeridas para configurar o agente, elas serão iguais nos três sistemas operacionais utilizados aqui.
Crie o diretório dos arquivos auxiliares do agente
mkdir -p /etc/zabbix/zabbix_agentd.conf.d
mkdir -p /etc/zabbix/zabbix_scriptsEdite o arquivo de configuração
nano /etc/zabbix/zabbix_agentd.conf
# Edite os parâmetros indicados aqui.
# Os outros podem ser mantidos nos valores padrões
#
# Hostname=> Use o IP ou FQDN da máquina que eestá sendo monitorada
# Server=> Use o IP ou FQDN do servidor Zabbix
Hostname = this.machine
Server = zabbix.int.example.com
ServerActive = zabbix.int.example.com
LogRemoteCommands = 1
EnableRemoteCommands = 1
StartAgents = 3
Include=/etc/zabbix/zabbix_agentd.conf.d/*.confInicie o serviço do agente
systemctl start zabbix-agent4. Gerenciando o serviço
Alterações na configuração do agente
Se for necessário modificar o arquivo de configuração do Zabbix, ele pode ser encontrado no caminho /etc/zabbix/zabbix_agentd.conf. Ao realizar qualquer alteração, é preciso reiniciar o agente.
Controlando a execução do serviço do agente
Ao modificar o arquivo de configuração mostrado no item anterior ou por razões fora do escopo deste guia pode ser necessário parar ou reiniciar o serviço usado pelo agente do Zabbix. Os comandos a seguir podem ser utilizados:
Para encerrar a execução do agente:
systemctl stop zabbix-agentPara reiniciar o agente:
systemctl restart zabbix-agentPara encerrar a execução do agente:
systemctl stop zabbix-agent
Zabbix: Instalando o agente em clientes windows
1. Introdução
Zabbix é uma solução de código aberto para monitoramento de dispositivos e aplicações, sendo capaz de monitorar parâmetros utilizando agentes em diversas plataformas de sistemas operacionais, além de protocolos como SNMP, IPMI, JMX, entre outros.
Este documento visa a orientação para a instalação do agente do Zabbix. Ele é utilizado pelo servidor para monitorar ativos e reportar sua disponibilidade permitindo uma visão proativa do parque tecnológico.
2. Ferramentas utilizadas
Este tutorial descreve a instalação do agente no sistema operacional Windows e, apesar da edição utilizada ter sido o Windows 7, pode ter seus passos utilizados para instalar o agente no Windows Server 2008 e 2012, Windows 8/8.1 e Windows 10. Também é abordada a questão de edição posterior à instalação e o controle do processo do agente.
Os softwares utilizados na produção deste tutorial é apresentado a seguir:
- Microsoft Windows 7
- Zabbix Agent 3.2.3
3. Configurando o serviço
Estes procedimentos devem ser realizados na máquina a ser monitorada, usando um usuário com permissões administrativas.
3.1. Faça download do arquivo de instalação
Para obter a versão mais atual do software, faça o download do instalador do agente de acordo com a arquitetura do sistema operacional (32 bits ou 64 bits), acessando o link http://suiviperf.com/zabbix/index.php

3.2. Instale o agente
Uma vez que o download tenha sido concluído, execute a instalação do agente.
3.2.1. Na primeira tela, clique em "Next"

3.2.2. Marque o checkbox "I accept the terms in the License Agreement" e clique em "Next"

3.2.3. Insira as informações requeridas, conforme a imagem a seguir, e clique em "Next"

3.2.4. Nesta página, clique em "Next" somente.

3.2.5. Nesta página, clique em "Install".

3.2.6 O UAC (Controle de Conta de Usuário) vai solicitar permissão para prosseguir com a instalação. Clique em "Sim".

A instalação será iniciada e a tela a seguir será exibida:

3.2.7. Clique em "Finish"

3.3 Configure o firewall
Caso o firewall esteja ativo, configure-o para permitir a conexão entre o servidor e o agente. Será necessária liberar o acesso a porta 10050/TCP.
4. Gerenciando o serviço
4.1. Alterações na configuração do agente
Se for necessário modificar o arquivo de configuração do Zabbix, ele pode ser encontrado no caminho %programfiles%\zabbix agent\zabbix_agentd.conf. Ao realizar qualquer alteração, é preciso reiniciar o agente.
4.2. Controlando a execução do serviço do agente
Ao modificar o arquivo de configuração mostrado no item anterior ou por razões fora do escopo deste guia pode ser necessário parar ou reiniciar o serviço usado pelo agente do Zabbix. Os comandos a seguir podem ser utilizados:
4.2.1. Acesse o painél de controle dos serviços, digitando "services.msc" na barra de buscas:

4.2.2. Na janela aberta, clique em Zabbix Agent.
“Zabbix Agent” será mostrado sob o campo “Nome” e provavelmente, será o último item mostrado. Será preciso usar a barra de rolagem para ir até o fim da lista de serviços

Na parte lateral da página existem controles para encerrar ou reiniciar a execução do agente (setas azuis)
Zabbix: Instalando o proxy
1. Introdução
Zabbix é uma solução de código aberto para monitoramento de dispositivos e aplicações, sendo capaz de monitorar parâmetros utilizando agentes em diversas plataformas de sistemas operacionais, além de protocolos como SNMP, IPMI, JMX, entre outros.
É uma plataforma bastante difundida e não está limitada a ativos de TIC, apenas. Pode ser utilizado em diversas áreas, pois o seu método de coleta é flexível e permitindo personalizá-lo de acordo com necessidades de monitoramento do ambiente.
2. Ferramentas utilizadas
Os softwares utilizados na produção deste tutorial é apresentado a seguir:
- CentOS 7
- Zabbix 3.4.1
- SQLite3
O ambiente utilizado é apresentado a seguir:
- Uma MV, com o sistema operacional CentOS 7, destinada ao servidor proxy do Zabbix
A instalação do CentOS 7 utilizada para validar esse tutorial foi a Minimal-1611. A ISO dessa versão pode ser baixada através deste link.
3. Configurando o serviço
Todos os comandos executados nesse tutorial foram executados com o usuário root.
Passos preparatórios
3.1. Após a instalação do CentOS, execute o comando abaixo para atualizar os pacotes presentes no sistema:
yum update3.2. Habilite o modo permissivo do SELinux, com os comandos abaixo:
sed s/SELINUX=enforcing/SELINUX=permissive/g -i /etc/selinux/config
setenforce 03.3. Adicione o repositório do Zabbix e MariaDB:
URL='https://repo.zabbix.com/zabbix/3.4/rhel/7/x86_64/zabbix-release-3.4-2.el7.noarch.rpm'
rpm -ivh "$URL" # Adiciona o repositório do zabbix3.4. Instalar o agente do Zabbix
yum install zabbix-agent zabbix-get # Instala o agente do zabbix
systemctl enable zabbix-agent # Configura o systemd para iniciar o agente do zabbix após o boot
Instalando o banco de dados
3.5. Após a instalação do CentOS, execute o comando abaixo para atualizar os pacotes presentes no sistema:
yum install sqlite -y
Instalando o proxy do Zabbix
3.6. Após a instalação do CentOS, execute o comando abaixo para atualizar os pacotes presentes no sistema:
yum install zabbix-proxy-sqlite zabbix-get zabbix-agent -y3.7. Vamos criar os diretórios a serem utilizados pelo proxy:
mkdir /etc/zabbix/{default,zabbix_proxy.conf.d}
chown zabbix:root -P /etc/zabbix/
touch /var/log/zabbix/snmptrap.log
chown zabbix:zabbix /var/log/zabbix/snmptrap.log3.8. configurar a base de dados do Zabbix e importar os schemas:
mkdir -p /app/zabbix
cd /usr/share/doc/zabbix-proxy-sqlite3-3*
zcat schema.sql.gz | sqlite3 /app/zabbix/proxy.db3.9. alterar os parâmetros do banco de dados no arquivo de configuração /etc/zabbix/zabbix_server.conf:
cd /etc/zabbix
cp *.conf default/
sed s/'# ProxyMode=0'/'ProxyMode=0'/g -i zabbix_proxy.conf
sed s/'LogFileSize=0'/'LogFileSize=128'/g -i zabbix_proxy.conf
sed s/'# StartPollers=5'/'StartPollers=35'/g -i zabbix_proxy.conf
sed s/'Server=127.0.0.1'/'Server=SERVIDOR_ZABBIX'/g -i zabbix_proxy.conf
sed s/'DBName=zabbix_proxy'/'DBName=\/app\/zabbix\/proxy.db'/g -i zabbix_proxy.conf
sed s/'# StartPollersUnreachable=1'/'StartPollersUnreachable=70'/g -i zabbix_proxy.conf
sed s/'Hostname=Zabbix proxy'/Hostname=$(hostname)/g -i zabbix_proxy.conf
sed s/'# StartIPMIPollers=0'/'StartIPMIPollers=5'/g -i zabbix_proxy.conf
sed s/'# ProxyLocalBuffer=0'/'ProxyLocalBuffer=360'/g -i zabbix_proxy.conf
sed s/'# ConfigFrequency=3600'/'ConfigFrequency=60'/g -i zabbix_proxy.conf
sed s/'# StartHTTPPollers=1'/'StartHTTPPollers=10'/g -i zabbix_proxy.conf
sed s/'# ProxyOfflineBuffer=1'/'ProxyOfflineBuffer=720'/g -i zabbix_proxy.conf
sed s/'# HeartbeatFrequency=60'/'HeartbeatFrequency=30'/g -i zabbix_proxy.conf
sed s/'# DataSenderFrequency=1'/'DataSenderFrequency=45'/g -i zabbix_proxy.conf
sed s/'# StartTrappers=5'/'StartTrappers=15'/g -i zabbix_proxy.conf
sed s/'# StartPingers=1'/'StartPingers=5'/g -i zabbix_proxy.conf
sed s/'# StartVMwareCollectors=0'/'StartVMwareCollectors=10'/g -i zabbix_proxy.conf
sed s/'# VMwareTimeout=10'/'VMwareTimeout=19'/g -i zabbix_proxy.conf
sed s/'# StartSNMPTrapper=0'/'StartSNMPTrapper=1'/g -i zabbix_proxy.conf
sed s/'# StartDBSyncers=4'/'StartDBSyncers=8'/g -i zabbix_proxy.conf
sed s/'# CacheSize=8M'/'CacheSize=32M'/g -i zabbix_proxy.conf
sed s/'# HistoryIndexCacheSize=4M'/'HistoryIndexCacheSize=16M'/g -i zabbix_proxy.conf
sed s/'# HistoryCacheSize=16M'/'HistoryCacheSize=64M'/g -i zabbix_proxy.conf
sed s/'\/var\/log\/snmptrap\/snmptrap.log'/'\/var\/log\/zabbix\/snmptrap.log'/g -i zabbix_proxy.conf
sed s/'Timeout=4'/'Timeout=19'/g -i zabbix_proxy.conf
sed s/'ExternalScripts=\/usr\/lib\/zabbix\/externalscripts'/'ExternalScripts=\/app\/zabbix\/externalscripts'/g -i zabbix_proxy.conf
sed s/'# Include=\/usr\/local\/etc\/zabbix_proxy.conf.d\/*.conf'/'\/etc\/zabbix_proxy.conf.d\/*.conf'/g -i zabbix_proxy.conf
Substitua “SERVIDOR_ZABBIX” pelo IP ou FQDN do servidor do zabbix configurado anteriormente.
3.10. Permita os serviços no Firewall
firewall-cmd --permanent --add-port=10051/tcp # configura o firewalld para permitir conexões ao proxy do zabbix
firewall-cmd --permanent --add-port=10050/tcp # configura o firewalld para permitir conexões ao agente do zabbix
firewall-cmd --reload3.11. Configure o serviço do servidor e agente:
systemctl enable zabbix-proxy zabbix-agent # Configura o systemd para iniciar os serviços do zabbix após o boot
systemctl start zabbix-proxy zabbix-agent # Inicia os serviços imediatamenteZabbix: Instalando o servidor
1. Introdução
Zabbix é uma solução de código aberto para monitoramento de dispositivos e aplicações, sendo capaz de monitorar parâmetros utilizando agentes em diversas plataformas de sistemas operacionais, além de protocolos como SNMP, IPMI, JMX, entre outros.
É uma plataforma bastante difundida e não está limitada a ativos de TIC, apenas. Pode ser utilizado em diversas áreas, pois o seu método de coleta é flexível e permitindo personalizá-lo de acordo com necessidades de monitoramento do ambiente.
2. Ferramentas utilizadas
Os softwares utilizados na produção deste tutorial é apresentado a seguir:
- CentOS 7
- Zabbix 3.4.1
- MariaDB 10.3.9-1.el7.centos
O ambiente utilizado é apresentado a seguir:
- Uma MV, com o sistema operacional CentOS 7, destinada ao banco de dados
- Uma MV, com o sistema operacional CentOS 7, destinada ao servidor e interface Web do Zabbix
A instalação do CentOS 7 utilizada para validar esse tutorial foi a Minimal-1611. A ISO dessa versão pode ser baixada através deste link.
3. Configurando o serviço
Todos os comandos executados nesse tutorial foram executados com o usuário root.
3.1. Instalando o servidor de banco de dados
Passos preparatórios
3.1.1. Após a instalação do CentOS, execute o comando abaixo para atualizar os pacotes presentes no sistema:
yum update3.1.2. Habilite o modo permissivo do SELinux, com os comandos abaixo:
sed s/SELINUX=enforcing/SELINUX=permissive/g -i /etc/selinux/config
setenforce 03.1.3. Adicione os repositórios do Zabbix e MariaDB:
URL='https://repo.zabbix.com/zabbix/3.4/rhel/7/x86_64/zabbix-release-3.4-2.el7.noarch.rpm'
rpm -ivh "$URL" # Adiciona o repositório do zabbix
printf '[mariadb]\nname = MariaDB\nbaseurl = http://yum.mariadb.org/10.3/centos7-amd64\ngpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB\ngpgcheck=1\n' > /etc/yum.repos.d/MariaDB.repo3.1.4. Instalar o agente do Zabbix
yum install zabbix-agent zabbix-get # Instala o agente do zabbix
systemctl enable zabbix-agent # Configura o systemd para iniciar o agente do zabbix após o bootCaso o local do armazenamento dos arquivos seja numa partição separada, insira a linha correta no fstab, definindo como ponto de montagem o diretório do mysql e monte-a digitando o comando mount -a
3.1.5. Instalar o MariaDB
yum install mariadb-server mariadb-libs mariadb -y # Instala o servidor
chown -R mysql:mysql /var/lib/mysql # Configura as permissões no diretório usado pelo mariadb
systemctl enable mariadb # Configura o systemd para iniciar o mariadb após o boot
systemctl start mariadb # Iniciar o serviço do mariadb imediatamente3.1.6. Permita os serviços no Firewall
firewall-cmd --permanent --add-port=3306/tcp # configura o firewalld para permitir conexões ao mariadb
firewall-cmd --permanent --add-port=10050/tcp # configura o firewalld para permitir conexões ao agente do zabbix
firewall-cmd --reloadConfigure o servidor de banco de dados
3.1.7. Complete a instalação do MariaDB:
mysql_secure_installationCom o comando acima iremos configurar a senha do usuário root para acessar o MySQL.
# Enter current password for root (enter for none): <ENTER>
# Change the root password? [Y/n] <Y>
# New password: <DIGITE UMA SENHA SEGURA>
# Re-enter new password: <DIGITE A SENHA NOVAMENTE>
# Remove anonymous users? [Y/n] <Y>
# Disallow root login remotely? [Y/n] <Y>
# Remove test database and access to it? [Y/n] <Y>
# Reload privilege tables now? [Y/n] <Y>Para manter a segurança num nível aceitável, crie uma senha segura, com no mínimo 8 dígitos, contendo letras maiúsculas e minúsculas e caracteres especiais.
Observe também que esta senha deve ser guardada em local seguro para possíveis acesso e manutenções.
3.1.8. Crie a base de dados para o Zabbix
Acesse o mariadb como root:
mysql -uroot -pDigite a senha cadastrada no passo anterior. Deverá aparecer o prompt da console do MySQL. Iremos criar a base de dados que será utilizada pelo Zabbix:
|
mysql> mysql> mysql> |
create database BASE_ZABBIX; grant all privileges on BASE_ZABBIX.* to 'USUARIO_ZABBIX'@'%' identified by 'SENHA_ZABBIX'; quit; |
O comando ‘create database’ cria a base de dados para o zabbix. Observe que o termo “base_zabbix” deve ser substituído pelo nome escolhido.
O comando iniciando com ‘grant all privileges‘ concede permissão para o usuário do zabbix com a senha a ser digitada no lugar de "senha_zabbix". Observe que o termo “usuario_zabbix” deve ser substituído pelo nome do usuário que o servidor irá utilizar ao se conectar à base de dados.
Para manter a segurança num nível aceitável, crie uma senha segura, com no mínimo 8 dígitos, contendo letras maiúsculas e minúsculas e caracteres especiais.
Observe também que esta senha deve ser guardada em local seguro para possíveis acesso e manutenções.
Essas informações serão utilizadas para o acesso a base de dados no arquivo de configuração do servidor Zabbix.
3.2. Instalando o servidor do Zabbix
Passos preparatórios
3.2.1. Após a instalação do CentOS no servidor, execute o comando abaixo para atualizar os pacotes presentes no sistema:
yum update3.2.2. Habilite o modo permissivo do SELinux, com os comandos abaixo:
sed s/SELINUX=enforcing/SELINUX=permissive/g -i /etc/selinux/config
setenforce 03.2.3. Adicione os repositórios do Zabbix e MariaDB:
URL='https://repo.zabbix.com/zabbix/3.4/rhel/7/x86_64/zabbix-release-3.4-2.el7.noarch.rpm'
rpm -ivh "$URL" # Adiciona o repositório do zabbix
printf '[mariadb]\nname = MariaDB\nbaseurl = http://yum.mariadb.org/10.3/centos7-amd64\ngpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB\ngpgcheck=1\n' > /etc/yum.repos.d/MariaDB.repo3.2.4. Instale os pacotes necessários
yum install wget unzip net-snmp net-snmp-utils -y # Instala dependências do SNMP
yum install zabbix-agent zabbix-get -y # Instala o agente do zabbix
yum install zabbix-server-mysql mariadb -y # Instala as bibliotecas do mariadb e o servidor zabbix
yum install zabbix-web-mysql -y # Instala a interface web do servidor zabbix3.2.5. Permita os serviços no Firewall
firewall-cmd --permanent --add-port=10050/tcp # configura o firewalld para permitir conexões ao agente do zabbix
firewall-cmd --permanent --add-port=10051/tcp # configura o firewalld para permitir conexões ao servidor do zabbix
firewall-cmd --permanent --add-service=snmp # configura o firewalld para permitir conexões snmp
firewall-cmd --permanent --add-service=snmptrap # configura o firewalld para permitir conexões snmp
firewall-cmd --reload3.2.6. Configure as MIBs do SNMP
cd /usr/share/snmp/mibs/
wget -c -m ftp://ftp.cisco.com/pub/mibs/v2/
mv ftp.cisco.com/pub/mibs/v2/* .
rm -fr ftp.cisco.com/
for line in $(ls *.my); do base=$(echo $line|cut -d'.' -f1); mv $line $base; donecd /usr/share/snmp/mibs/
wget -c https://github.com/librenms/librenms-mibs/archive/master.zip -O Cisco-SB-MIB.zip
unzip -jo Cisco-SB-MIB.zip
rm -fr Cisco-SB-MIB.zip
for line in $(ls *.mi2); do base=$(echo $line|cut -d'.' -f1); mv -n $line $base; doneConfigure a base de dados
3.2.7. Importar os schemas:
cd /usr/share/doc/zabbix-server-mysql-3.*
zcat create.sql.gz | mysql -h IP_SERVIDOR_BANCO -u USUARIO_ZABBIX -p BASE_ZABBIX A senha solicitada, assim como os itens "USUARIO_ZABBIX" e "BASE_ZABBIX" devem ser os mesmos configurados no passo "Crie a base de dados para o Zabbix".
Substitua o “IP_SERVIDOR_BANCO” pelo IP do servidor do banco de dados configurado anteriormente.
Configure o servidor zabbix
3.2.8. Será necessário alterar alguns parâmetros do banco de dados no arquivo de configuração /etc/zabbix/zabbix_server.conf:
cd /etc/zabbix # Entra no diretório do zabbix
mkdir -p original # Cria diretório para backup, se não existir
cp zabbix*.conf original/ # Copia os arquivos de configuração originais para pasta criada
sed s/'LogFileSize=0'/'LogFileSize=128'/g -i zabbix_server.conf # Define o tamanho máximo de cada arquivo de log
sed s/'Timeout=4'/'Timeout=20'/g -i zabbix_server.conf # Define o timeout da conexão ao cliente
sed s/'# StartSNMPTrapper=0'/'StartSNMPTrapper=1'/g -i zabbix_server.conf # Define se o SNMP trapper será ativado
sed s/'# SenderFrequency=30'/'SenderFrequency=60'/g -i zabbix_server.conf # Frequencia submetida aos senders
sed s/'# StartDBSyncers=4'/'StartDBSyncers=8'/g -i zabbix_server.conf # Define a quantidade de sicronizadores entre a aplicação e o bd
sed s/'# StartPollers=5'/'StartPollers=35'/g -i zabbix_server.conf # Quantidade de pollers multipropósito (para java, ipmi e etc)
sed s/'# HistoryCacheSize=16M'/'HistoryCacheSize=128M'/g -i zabbix_server.conf # Tamanho do cache para histórico de alterações
sed s/'# HistoryIndexCacheSize=4M'/'HistoryIndexCacheSize=64M'/g -i zabbix_server.conf # Tamanho do cache para o indice do histórico
sed s/'# TrendCacheSize=4M'/'TrendCacheSize=64M'/g -i zabbix_server.conf # Tamanho do cache usado para armazenar tendências
sed s/'# ValueCacheSize=8M'/'ValueCacheSize=64M'/g -i zabbix_server.conf # Tamanho do cache de valores
sed s/'# CacheSize=8M'/'CacheSize=512M'/g -i zabbix_server.conf # Tammanho máximo que todos os caches, somados, podem alcançar
sed s/'# StartVMwareCollectors=0'/'StartVMwareCollectors=16'/g -i zabbix_server.conf # Quantidade de coletores de dados do vmware
sed s/'# VMwareCacheSize=8M'/'VMwareCacheSize=16M'/g -i zabbix_server.conf # Cache para os dados de vmware coletados
sed s/'# VMwareTimeout=10'/'VMwareTimeout=30'/g -i zabbix_server.conf # Define timeout para conexão ao agente do vmware
sed s/'# DBHost=localhost'/'DBHost=IP_SERVIDOR_BANCO'/g -i zabbix_server.conf # Servidor onde está a BD do zabbix. Substitua IP_SERVIDOR_BD pelo IP correto
sed s/'DBName=zabbix'/'DBName=BASE_ZABBIX'/g -i zabbix_server.conf # BD a ser utilizada pelo zabbix. Substitua pelo nome correto
sed s/'# DBPassword='/'DBPassword=SENHA_ZABBIX'/g -i zabbix_server.conf # Senha para conexão a BD. Substitua pela senha correta
sed s/'DBUser=zabbix'/'DBUser=USUARIO_ZABBIX'/g -i zabbix_server.conf # Usuário para conexão a BD. Substitua pelo nome corretoA senha solicitada, assim como os itens "USUARIO_ZABBIX" e "BASE_ZABBIX" devem ser os mesmos configurados no passo "Crie a base de dados para o Zabbix".
Substitua o “IP_SERVIDOR_BANCO” pelo IP do servidor do banco de dados configurado anteriormente.
3.2.9. Configure o serviço do servidor e agente:
systemctl enable zabbix-agent zabbix-server-mysql # Configura o systemd para iniciar os serviços do zabbix após o boot
systemctl start zabbix-server zabbix-agent # Inicia os serviços imediatamenteRealizada a instalação da base de dados e do servidor Zabbix, o próximo passo é configurar e instalar a interface web.
3.3. Instalando a interface web servidor do Zabbix
A interface web e o servidor podem ser instalados na mesma máquina. No entanto, esse procedimento não é recomendado em ambientes de alta disponibilidade.
Passos preparatórios
3.3.1. Após a instalação do CentOS no servidor, execute o comando abaixo para atualizar os pacotes presentes no sistema:
yum update3.3.2. Habilite o modo permissivo do SELinux, com os comandos abaixo:
sed s/SELINUX=enforcing/SELINUX=permissive/g -i /etc/selinux/config
setenforce 03.3.3. Adicione os repositórios do Zabbix e MariaDB:
URL='https://repo.zabbix.com/zabbix/3.4/rhel/7/x86_64/zabbix-release-3.4-2.el7.noarch.rpm'
rpm -ivh "$URL" # Adiciona o repositório do zabbix
printf '[mariadb]\nname = MariaDB\nbaseurl = http://yum.mariadb.org/10.3/centos7-amd64\ngpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB\ngpgcheck=1\n' > /etc/yum.repos.d/MariaDB.repo3.3.4. Instale os pacotes necessários
yum install zabbix-agent zabbix-get -y # Instala o agente do zabbix
yum install mariadb zabbix-web-mysql -y # Instala as bibliotecas do mariadb e a aplicação web do zabbix3.3.5. Permita o serviço no Firewall
firewall-cmd --permanent --add-service=http # configura o firewalld para permitir conexões http
firewall-cmd --permanent --add-service=https # configura o firewalld para permitir conexões https
firewall-cmd --reloadConfigure a aplicação web do Zabbix
3.3.6. Edite o arquivo contendo as definições do site do zabbix
cd /etc/httpd/conf.d/ # Diretório de configuração dos sites do apache
sed s/'# php_value'/'php_value'/g -i zabbix.conf # Ativa as definições do PHP dentro do arquivo
sed s/'timezone.*'/'timezone America\/Recife'/g -i zabbix.conf # Define o timezone correto
sed s/'Alias'/'# Alias'/g -i zabbix.conf # Retira o alias "/zabbix/"
sed '6i Alias / /usr/share/zabbix/' -i zabbix.conf # Adiciona o alias "/", redirecionando o indice no referido diretório3.3.7. Crie o arquivo de configuração da aplicação web do zabbix
vi /etc/zabbix/web/zabbix.conf.php
As configurações deverão ficar conforme o exemplo abaixo:
<?php
// Zabbix GUI configuration file.
global $DB;
$DB['TYPE'] = 'MYSQL';
$DB['SERVER'] = 'IP_SERVIDOR_BANCO';
$DB['PORT'] = '0';
$DB['DATABASE'] = 'BASE_ZABBIX';
$DB['USER'] = 'USUARIO_ZABBIX';
$DB['PASSWORD'] = 'SENHA_ZABBIX';
// Schema name. Used for IBM DB2 and PostgreSQL.
$DB['SCHEMA'] = '';
$ZBX_SERVER = 'localhost';
$ZBX_SERVER_PORT = '10051';
$ZBX_SERVER_NAME = 'zabbix.int.example.com';
$IMAGE_FORMAT_DEFAULT = IMAGE_FORMAT_PNG;Os itens "USUARIO_ZABBIX" , "SENHA_ZABBIX" e "BASE_ZABBIX" devem ser os mesmos configurados no passo "Crie a base de dados para o Zabbix".
Em $ZBX_SERVER, substitua "localhost" pelo IP ou FQDN da máquina onde o servidor Zabbix está instalado.
Em $ZBX_SERVER_NAME, substitua "zabbix.int.example.com" pelo nome a ser dado ao servidor.
Substitua o “IP_SERVIDOR_BANCO” pelo IP do servidor do banco de dados configurado anteriormente.
3.3.8. Configure o serviço utilizado pela interface gráfica:
systemctl enable httpd # Configura o systemd para iniciar o apachea pós o boot
systemctl start httpd # Inicia osserviço imediatamente3.4. Configurações adicionais
Passos preparatórios
3.4.1. Neste momento, abra o seu navegador favorito e insira o endereço do teu servidor, conforme o exemplo abaixo:
https://IP-DO-SERVIDOR/
Será mostrada uma tela solicitando credenciais. Faça login no sistema com o usuário Admin e a senha zabbix.
Configure o inventário e monitoramento do servidor
3.4.2. Primeiro, vamos habilitar a capacidade do Zabbix de fazer inventário de alguns itens sobre os dispositivos monitorados:
Clique em Administration > General. No dropbox à direita, clique em Others.
3.4.3. Feito isso, vamos habilitar o monitoramento do próprio servidor:
Clique em Configuration > Hosts, marque o checkbox ao lado de “Zabbix Server” e clique no botão “Enable”.
Zabbix: Templates para o Bacula/Bareos
1. Introdução
Zabbix é uma solução de código aberto para monitoramento de dispositivos e aplicações, sendo capaz de monitorar parâmetros utilizando agentes em diversas plataformas de sistemas operacionais, além de protocolos como SNMP, IPMI, JMX, entre outros.
O Bareos, assim como o Bacula, é uma solução permite a realização de trabalhos de backup e restauração de dados. São suportadas máquinas clientes Linux e Windows.
Este documento destina-se a demonstração dos procedimentos de instalação e configuração básica da solução de backup Bareos. Tal solução permite a realização de trabalhos de backup e restauração de dados. São suportadas máquinas clientes Linux e Windows.
2. Ferramentas utilizadas
Este template foi homologado com os sistemas operacionais listados:
- Centos 6
- Centos 7
- Debian Linux 7
- Debian Linux 8
Versões do Bacula Agent testadas:
- Agente do bacula, versão 5.x
- Agente do bacula, versão 7.x
Versões do Agente do Zabbix testadas:
- Zabbix Agent 2.4.x
- Zabbix Agent 3.2.x
- Zabbix Agent 3.4.x
3. Visão geral do Bareos/Bacula
O Bareos e o Bacula são divididos em três componentes principais: o Director, o Storage Daemon e o File Daemon.
O Director é o componente central, atuando como controlador que contata clientes e salva dados de backups nos armazenamentos. O Storage Daemon é o armazenamento dos dados de backup e é independente do Director pois nem sempre o mesmo servidor que controla é o mesmo que armazena os backups diretamente. E finalmente, o File Daemon é o componente cliente, aquele que recebe conexões do Director e provê a este os arquivos de backup referente aos conjuntos de arquivos configurados.
Adicionalmente, há o Console, que é um componente utilizado para acessar configurações, verificar status e fazer alterações nos parâmetros do servidor via linha de comando, mas que não será abordado neste escopo.
Estes procedimentos devem ser realizados na interface web do servidor, usando um usuário com permissões suficientes.
4. Templates para os componentes
Conforme a seção anterior, o Bareos e o Bacula são divididos em componentes, sendo necessário um template específico para o monitoramento de cada um deles.
4.1. Template para o agente (bareos-fd ou bacula-fd)
Itens monitorados
Utilizando este template as seguintes perguntas poderão ser respondidas:
- É possível, a partir de uma máquina da rede, se conectar a porta do bacula-fd no computador cliente?
- O bacula-fd está escutando na sua respectiva porta no computador cliente?
- Quantos processos do bacula-fd estão executando no computador cliente?
Pré requisitos:
Ter instalado, no dispositivo a ser monitorado, os seguintes softwares:
- zabbix-agent
- bacula-fd
Procedimento a ser realizado na máquina monitorada: Nenhum procedimento necessário
Procedimento a ser realizado na interface web do Zabbix: Nenhum procedimento necessário
- Importar o arquivo XML do template (listado a seguir)
- Adicionar o template ao host monitorado
Arquivo XML do template: Última versão do template do cliente
4.2. Template para o storage (bareos-sd ou bacula-sd)
Itens monitorados
Utilizando este template as seguintes perguntas poderão ser respondidas:
- É possível, a partir de uma máquina da rede, se conectar a porta do bacula-sd no servidor?
- O bacula-sd está escutando na sua respectiva porta no servidor?
- Quantos processos do bacula-sd estão executando no servidor?
Pré requisitos:
Ter instalado, no dispositivo a ser monitorado, os seguintes softwares:
- zabbix-agent
- bacula-sd
Procedimento a ser realizado na máquina monitorada: Nenhum procedimento necessário
Procedimento a ser realizado na interface web do Zabbix: Nenhum procedimento necessário
- Importar o arquivo XML do template (listado a seguir)
- Adicionar o template ao host monitorado
Arquivo XML do template: Última versão do template do storage
4.3. Template para o director (bareos-dir ou bacula-dir)
Itens monitorados
Utilizando este template as seguintes perguntas poderão ser respondidas:
- É possível, a partir de uma máquina da rede, se conectar a porta do bacula-dir no servidor?
- O bacula-dir está escutando na sua respectiva porta no servidor?
- Quantos processos do bacula-dir estão executando no servidor?
- Qual o status, a duração e o tamanho do último backup incremental?
- Qual o status, a duração e o tamanho do último backup diferencial?
- Qual o status, a duração e o tamanho do último completo?
- Quanto tempo se passou desde a última execução de cada job?
Pré requisitos:
Ter instalado, no dispositivo a ser monitorado, os seguintes softwares:
- zabbix-agent
- bacula-dir
Procedimento a ser realizado na máquina monitorada:
- Criar um diretório para o script de monitoramento e o de descoberta dos jobs de backup
- Fazer download do script de monitoramento e o de descoberta dos jobs de backup para o diretório criado
- Ajustar os parâmetros de usuário para refletir a localização dos scripts, caso necessário
- Verificar a necessidade de configurações adicionais como o uso do sudo e permissões de execução dos scripts
Procedimento a ser realizado na interface web do Zabbix:
- Importar o arquivo XML do template (listado a seguir)
- Adicionar o template ao host monitorado
Arquivos do template: Última versão do template do director
Questões e dicas
Capítulo destinado a mostrar soluções conhecidas, de forma compacta, para alguns problemas encontrados no dia a dia do suporte às redes de computadores
Cliente: SSSD
Situações frequentes
001. Não é possível fazer login usando as credenciais do domínio quando o SSSD é utilizado
Verifique sempre a conectividade, especialmente a qualidade do link e o firewall do lado do cliente e do servidor antes de realizar o procedimento a seguir
A conexão iniciada pelo SSSD pode ser incapaz de recuperar os dados necessários para a autenticação do usuário quando o ticket kerberos da máquina expira. É possível verificar se isso acontece ao executar o seguinte comando:
systemctl status sssdObserve se a saída do comando contém o padrão indicado a seguir:
mar 21 13:26:44 hostname-da-maquina [sssd[krb5_child[46811]: Ticket expired
mar 21 13:27:56 hostname-da-maquina [sssd[krb5_child[46818]: Ticket expired
mar 21 13:29:05 hostname-da-maquina [sssd[krb5_child[46824]: Ticket expiredHavendo a confirmação do problema, execute os comandos (como usuário root) para que um novo ticket seja obtido:
service sssd stop;
rm -rf /var/lib/sss/db/* /var/lib/sss/mc/*;
service sssd startServidores: BareOS/Bacula
Situações frequentes
001. Alterei o tamanho máximo dos volumes na definição do pool, mas o limite antigo continua a ser aplicado ao realizar o backup.
Apesar do novo valor ter sido configurado corretamente, ele não irá funcionar para os volumes já criados, os quais precisam ser atualizados manualmente.
No shell, abra o console do BareOS/Bacula
bconsolePara cada volume a ser atualizado, digite:
update volume=Vol001-Pool001 maxvolbytes=200GNeste exemplo, o tamanho máximo do volume "Vol001-Pool001" foi alterado para 200 GB
Servidores: Samba
Situações frequentes
001. Criei uma GPO para ativar a Assistência Remota do Windows mas não consigo conectar aos clientes.
Apesar da Política de Grupo ter sido configurada corretamente, a Assistência Remota não irá funcionar perfeitamente devido a uma incompatibilidade da interface U2U do Kerberos usado para a autenticação do referido recurso do Windows.
Para a execução com sucesso, é preciso:
- No Windows: Aplicar um hotfix disponível em neste link.
- No Samba, definir um Service Principal Name (SPN) para o usuário que vai receber a assistência.
Para que não seja necessário adicionar um SPN manualmente a cada usuário existente, crie um script com o conteúdo abaixo e execute. Adicionalmente, sua execução pode ser agendada no cron.
#!/bin/bash
filterString="k/|G/|Ad"
sambaTool=$(which samba-tool)
searchString="has no service"
user=""
# Loop para descobrir os usuários
for user in $( ${sambaTool} user list | grep -v "^[${filterString}]" )
do
# Procura um SPN configurado para o usuário
${sambaTool} spn list "${user}" | grep "${searchString}"
# Se o retorno for zero, não possui um SPN configurado
if [ $? == 0 ]
then
# Define um SPN. Ex: se o usuário for "teste", será definido "spn-teste"
${sambaTool} spn add spn-"${user}" "${user}"
# Avisa sobre a definição
echo "Um SPN foi definido para o usuário ${user}"
else
:
fi
doneServidores: SSH
Situações frequentes
001. A senha demora a ser solicitada quanto um acesso SSH é realizado
Verifique sempre a conectividade, especialmente a qualidade do link e o firewall do lado do cliente e do servidor antes de realizar o procedimento a seguir
As conexões a servidores via SSH podem sofrer atrasos enquanto o servidor e o cliente tentam acordar se será utilizado o GSSAPI como método de autenticação. É possível verificar se isso acontece ao executar o seguinte comando:
ssh -vvv <ip do servidor>Se houver uma demora até a senha ser solicitada e existirem menções como "Unspecified GSS failure" ou "No Kerberos credentials available", desabilitar a GSSAPI pode ajudar a tornar o processo mais rápido.
Para desabilitar a autenticação com GSSAPI, execute os comandos como root:
sed -i '/GSSAPIAuthentication/s/^#//g' /etc/ssh/sshd_config
sed -i '/^GSSAPIAuthentication/s/yes/no/' /etc/ssh/sshd_config
systemctl reload sshdSistema: Discos e partições
Situações frequentes
001. Adicionei um novo disco a um computador ou máquina virtual e ele não aparece para uso.
Se o computador executar o sistema operacional Windows, será necessário reiniciá-lo.
Se o computador executar sistemas operacionais Linux
Como root, realize o seguinte procedimento para que o novo disco seja detectado sem a necessidade de reiniciar:
1. Descubra as interfaces dos adaptadores SCSI:
ls /sys/class/scsi_host
Anote a saída do comando. Ela deve ser parecida com: host0 host1.
2. Execute o comando para cada adaptador :
echo "- - -" > /sys/class/scsi_host/host0/scan
echo "- - -" > /sys/class/scsi_host/host1/scan
002. Aumentei o tamanho de um disco já existente numa máquina virtual linux e o tamanho não foi atualizado.
Para que o sistema detecte o novo tamanho do disco sem a necessidade de reiniciar a máquina, realize o seguinte procedimento:
Se o computador executar o sistema operacional Windows:
Na tela do Gerenciamento do Computador, clique com o botão direito em Gerenciamento de Disco e clique em Reescanear Discos.
OBS: Observe que o procedimento é suportado a partir do Windows Server 2008 e Windows 7
Se o computador executar sistemas operacionais Linux:
1. Como root, execute o comando para o disco que teve o tamanho alterado. Nesse exemplo, trata-se do disco /dev/sda:
echo 1 > /sys/block/sda/device/rescan
Nota: Se o tamanho não foi atualizado, tente novamente depois de realizar os passos da pergunta 001.
Sistema: Rede
Situações Frequentes
001. Como desativar o IPv6 no Linux?
Como root, execute os seguintes comandos:
echo "net.ipv6.conf.all.disable_ipv6=1" >> /etc/sysctl.conf
echo "net.ipv6.conf.default.disable_ipv6=1" >> /etc/sysctl.conf
sysctl -pSerá necessário reiniciar o serviço da rede para que a alteração entre em vigor.
Redes Virtuais Privadas
Capítulo destinado a receber tutoriais diversos relacionados a criação de VPNs, assim como ao acesso.
Configuração da VPN L2TP/IPsec num desktop Windows
1. Introdução
Uma Rede Virtual Privada, ou VPN, possibilita a criação de um canal de comunicação seguro, usando técnicas de criptografia e autenticação, permitindo assim a troca confiável de dados sobre redes públicas. Quando você conecta o seu dispositivo a uma VPN, ele age como se estivesse na mesma rede do sistema ao qual deseja se conectar e todo o tráfego de dados é enviado de forma segura por meio do canal criptografado.
Este documento visa a orientar a configuração de uma VPN do tipo acesso remoto, utilizando IPsec e L2TP.
Observe que todos os passos são obrigatórios.
2. Obtendo os dados
Certifique-se de que possui os dados necessários para configurar a VPN. Esses dados devem ter sido enviados pelo departamento de TI, que pode ser o DGTI ou CGTI ou mesmo DADT, dependendo do Campus no qual é lotado.
Dados da VPN
Confira se nos dados repassados a você existem os seguintes itens:
- endereço IP do servidor
- nome da conexão
- usuário
- senha
- chave PSK
Caso não possua os dados ou estejam incompletos, entre em contato com o departamento de TI do seu campus.
Dados do computador cliente
Certifique-se de saber qual Sistema Operacional é utilizado no seu desktop ou notebook no qual deseja conectar à VPN. Neste tutorial são abordados o Windows 7 e Windows 10, somente.
Caso deseje configurar o acesso à VPN em um sistema operacional diferentes dos abordados aqui, entre em contato com o departamento de TI do seu campus.
3. Configurando o acesso
Clique no Sistema Operacional que é utilizado no seu desktop ou notebook no qual deseja conectar à VPN.
Configurando o acesso no Windows 7
Configurando o acesso no Windows 10
3.1. Configurando o acesso no Windows 7
Para configurar a conexão no sistema operacional Windows 7, siga os passos a seguir.
3.1.1. Clique com o botão direito do mouse no ícone de rede na bandeja da barra de tarefas [1] e depois em "Abrir central de rede e compartilhamento"[2].

3.1.2. Clique em "Configurar nova conexão ou rede".

3.1.3. Selecione "Conectar a um local de trabalho" [1] e clique em "Avançar" [2].

3.1.4. Clique em "Usar a minha conexão com a Internet (VPN)".

Nesse momento, certifique-se de ter à mão os dados recebidos da equipe de TI.
3.1.5. Coloque o endereço IP do servidor que você recebeu como "Endereço na Internet" [1] e o nome da conexão em "Nome do destino" [2]. Marque a opção "Não conectar agora. Apenas configurar..." [3] e clique em "Avançar" [4].

3.1.6. Insira o usuário e senha recebidos nos campos “Nome de usuário” [1] e “Senha” [2], respectivamente. Marque a opção "Lembrar esta senha" [3] e clique em "Criar" [4].

3.1.7. Clique em “Fechar”

3.1.8. Abra a central de rede e compartilhamento (conforme descrito no passo nº 1) e clique em "Alterar as configurações do adaptador".

3.1.9. Clique com o botão direito do mouse no adaptador de rede VPN (ele terá o mesmo nome do item nome da conexão) [1] e então clique em "Propriedades" [2].

3.1.10. Mude para a aba "Segurança" [1].
3.1.10.1. Selecione o tipo de VPN "Protocolo de Túnel de Camada 2 com IPsec (L2TP/IPsec)" [2]. Clique em “Permitir estes protocolos” [3] e então marque somente a opção “Microsoft CHAP Versão 2 (MS-CHAP v2)” [4].
3.1.10.2. clique em "Configurações avançadas" [5].

3.1.10.3. Escolha "Usar chave pré-partilhada para autenticação" [1]. Em “Chave” [2], insira o valor do item “chave PSK” nos dados que você recebeu. Finalmente, clique em “Ok" [3] duas vezes.

3.1.11. Clique com o botão esquerdo do mouse no ícone de rede na bandeja da barra de tarefas [1], selecione a conexão VPN (ele terá o mesmo nome do item nome da conexão) [2] e clique em "Conectar" [3]. Na tela que será aberta, clique novamente em "Conectar".

3.1.12. Clique com o botão esquerdo do mouse no ícone de rede na bandeja da barra de tarefas. Se a conexão for estabelecida com sucesso, irá aparecer "Conectado".
3.2. Configurando o acesso no Windows 10
No momento, estamos escrevendo os passos necessários. Se for necessário realizar a configuração com o Windows 10, entre em contato com o departamento de TI do seu campus.
Habilitando a VPN do cliente no Cloudstack
1. Introdução
Uma Rede Virtual Privada, ou VPN, possibilita a criação de um canal de comunicação seguro, usando técnicas de criptografia e autenticação, permitindo assim a troca confiável de dados sobre redes públicas. Quando você conecta o seu dispositivo a uma VPN, ele age como se estivesse na mesma rede do sistema ao qual deseja se conectar e todo o tráfego de dados é enviado de forma segura por meio do canal criptografado.
Este documento visa a orientar a configuração de uma VPN do tipo acesso remoto, utilizando IPsec e L2TP.
Observe que todos os passos são obrigatórios.
2. Obtendo os dados
Certifique-se de que possui os dados necessários para configurar a VPN. Para este roteiro, os seguintes dados serão necessários:
- Acesso a interface Web do CDC
3. Configurando o acesso do usuário
Primeiro, abra um navegador da web, acesse https://compute.rnp.br, faça login.
Na superior esquerda, escolha o projeto então clique em "Network". Na tela que se abre, em "Select view" , escolha "VPN Users"
Na tela que se abre, clique "Add User" e preencha os campos solicitados (verifique observação). Clique em "Ok"
Se o usuário da VPN a ser criado tiver uma conta de acesso ao CDC, escolha o campo "Domain". Ao fazer isso, surgirá um novo campo, chamado "Account". Nele preencha a conta do usuário (por exemplo "paulo.jose@here.br")
3.1. Obtendo o IP e a chave PSK para a VPN
No mesmo projeto escolhido no passo anterior, clique em "Network". Na tela que se abre, em "Select view" , escolha "VPC".
Na tela que se abre, no VPC desejado, clique em "Configure". Em "Router", clique em "PUBLIC IP ADDRESSES" e será exibida uma lista com todos os IPs que estão sendo utilizados.
Clique no IP que tem a sinalização "[Source NAT]", na tela que se abre, clique em "VPN". Serão exibidas as informações sobre a VPN, as quais serão necessárias para a configuração do cliente.
Serviços de domínio
Capítulo destinado aos softwares provedores de serviços de domínio, como Samba e MS AD Directory Services
Cliente: Configuração do SSSD (controlador de domínio Samba4)
1. Introdução
O System Security Services Daemon é um pacote de software originalmente desenvolvido para o sistema operacional Linux que fornece um conjunto de daemons para gerenciar o acesso a diretórios remotos e mecanismos de autenticação. Funciona como um agregado de daemons que gerenciam mecanismos de autenticação remota, assim como serviços de diretórios que manipula diretamente o PAM e o NSS.
2. Obtendo os dados
Para que a configuração seja realizada com sucesso, certifique-se de:
-
Ter acesso administrativo ao computador no qual o SSSD será instalado
-
Saber a distribuição linux utilizada no computador no qual o SSSD será instalado
-
Saber o nome do domínio
-
Saber o(s) endereço(s) IP do(s) controlador(es) do domínio
-
Possuir um arquivo com o certificado da CA utilizada pelo servidor
- Possuir os dados de usuário e senha utilizados pelo SSSD
3. Executando a configuração
Instale os pacotes necessários para o funcionamento do serviço do SSSD. A lista varia conforme a distribuição.
3.1. Instalação dos pacotes
3.1.a. No Debian/Ubuntu:
apt install -y sudo cracklib-runtime ldap-utils libbasicobjects0 libc-ares2 libcollection4 \
libcrack2 libdhash1 libini-config5 libipa-hbac0 libldap-common libnl-3-200 libnl-route-3-200 \
libldb1 libnspr4 libnss-sss libntdb1 libopts25 libpwquality-common libpwquality1 libpam-pwquality \
libpath-utils1 libpam-sss libsss-sudo libpython2.7 libref-array1 libsasl2-modules-gssapi-mit \
libnss3 libsss-idmap0 libtalloc2 libtdb1 libtevent0 libwbclient0 ntp python-sss python-talloc \
samba-libs sssd sssd-ad sssd-ad-common sssd-common sssd-ipa sssd-krb5 sssd-krb5-common sssd-ldap\
sssd-proxy krb5-config krb5-user libgssrpc43.1.b. No Centos:
yum install -y sudo sssd ntp openldap sssd-ldap pam_ldap pam_krb5 krb5-workstation3.2. Configuração do sistema
3.2.1. Configuração do DNS
Para que os servidores utilizados por este serviço sejam resolvidos corretamente, defina as configurações de rede para utilizar o IP do controlador de domínios como o servidor DNS primário do computador cliente e o nome do domínio ao qual o computador será ingressado no domínio a ser utilizado para buscas.
Essa configuração pode ser realizada de formas diferentes. A forma recomendada difere de acordo com o sistemas operacional utilizado.
- No Debian/Ubuntu: Edite o arquivo /etc/network/interfaces
- No Centos: Utilize o comando
nmtui
3.2.2. Certificado da CA utilizado pelo samba
A comunicação entre o cliente e o servidor samba utiliza TLS para proteger os dados. Utilizando esta técnica, o cliente usa um certificado para se autenticar com o servidor.
Crie o arquivo /etc/ssl/private/sssd-ca.pem contendo o certificado da CA utilizado pelo samba.
3.2.3. Criação automática da pasta do usuário
Uma vez que o SSSD tenha autenticado os usuários no domínio e tenham acesso ao sistema, a pasta do usuário não será criada automaticamente.
Para habilitar a criação automática da pasta do usuário, siga o procedimento:
3.2.3.a. No Debian/Ubuntu
Execute o seguinte comando no shell do computador
nano /etc/pam.d/common-sessionInsira a linha a seguir após o primeiro bloco de comentários
|
session required pam_mkhomedir.so skel=/etc/skel/ umask=0022 |
3.2.3.b. No Centos
authconfig --update --enablesssd --enablesssdauth --enablemkhomedir3.3. Configuração do sudo
Execute o comando a seguir no shell do computador cliente:
Neste exemplo, aos membros do grupo chamado "EXEMPLO_SUDO", será permitido o uso do sudo. Substitua pelo grupo correto na hora da execução do comando
echo '%EXEMPLO_SUDO ALL=(ALL) ALL' > /etc/sudoers.d/ldap_sudo_group
chmod 0600 /etc/sudoers.d/ldap_sudo_groupO item iniciado por um símbolo de percentual (%EXEMPLO_SUDO) indica o nome do grupo que irá receber as permissões do sudo.
3.4. Configuração do kerberos
Cabe ao kerberos garantir a troca de chaves, de forma segura, entre os computadores de uma rede que o utilize. Para tal, é necessário configurar o cliente para se comunicar aos provedores deste serviço.
Execute o comando a seguir no shell do computador cliente:
nano /etc/krb5.confDeixe o arquivo conforme mostrado a seguir.
Neste exemplo, o nome do domínio utilizado foi "EXEMPLO.LOCAL". Altere o nome para o domínio correto.
Neste exemplo, o FQDN do servidor controlador de domínio utilizado foi "DC01.EXEMPLO.LOCAL". Altere o nome para o FQDN correto.
|
[logging] default = SYSLOG:NOTICE default = FILE:/var/log/krb5.log [libdefaults] default_realm = DOMINIO.LOCAL # MIT Kerberos Variables. krb5_config = /etc/krb.conf krb5_realms = /etc/krb.realms default_keytab_name = /etc/krb5.keytab dns_lookup_kdc = no dns_lookup_realm = no ticket_lifetime = 24h kdc_timesync = 1 ccache_type = 4 forwardable = true proxiable = true [realms] DOMINIO.LOCAL= { kdc = DC01.DOMINIO.LOCAL admin_server = DC01.DOMINIO.LOCAL default_domain = DOMINIO.LOCAL } [domain_realm] .ifpe.local = DOMINIO.LOCAL |
3.5. Configuração do SSSD
O SSSD é o serviço que realiza a autenticação em si, se apoiando na resolução de nomes e nas facilidades oferecidas pelo kerberos.
3.5.1. O arquivo de configuração principal
Execute o comando a seguir no shell do computador cliente:
touch /etc/sssd/sssd.conf
chmod 600 /etc/sssd/sssd.conf
nano /etc/sssd/sssd.confDeixe o arquivo conforme mostrado a seguir.
Neste exemplo, o nome do domínio utilizado foi "EXEMPLO.LOCAL". Altere o nome para o domínio correto.
Neste exemplo, o FQDN do servidor controlador de domínio utilizado foi "DC01.EXEMPLO.LOCAL". Altere o nome para o FQDN correto.
Substitua "CN=USUARIO_SSSD,OU=SUB,DC=DOMINIO,DC=LOCAL" e "XXXXX_SENHA_DO_SSSD_XXXXX" pelo CN e senha corretos
|
[sssd] debug_level = 7 reconnection_retries = 2 config_file_version = 2 sbus_timeout = 10 services = nss,pam domains = DOMINIO.LOCAL [nss] debug_level = 7 reconnection_retries = 2 filter_users = root, daemon, bin, sys, sync, games, man, lp, mail, news, uucp, proxy override_homedir = /home/%u.%d fallback_homedir = /home/%u default_shell = /bin/bash [pam] debug_level = 7 reconnection_retries = 2 pam_verbosity = 2 pam_id_timeout = 15 offline_credentials_expiration = 2 offline_failed_login_attempts = 2 offline_failed_login_delay = 2 [domain/DOMINIO.LOCAL] debug_level = 7 reconnection_retries = 2 enumerate = False cache_credentials = True entry_cache_timeout = 600 # access_provider = simple access_provider = ldap auth_provider = krb5 chpass_provider = krb5 id_provider = ldap krb5_server = DC01.DOMINIO.LOCAL krb5_realm = DOMINIO.LOCAL krb5_store_password_if_offline = True krb5_kpasswd = DC01.DOMINIO.LOCAL krb5_renew_interval = 30m krb5_renewable_lifetime = 7d ldap_default_bind_dn = CN=USUARIO_SSSD,OU=SUB,DC=DOMINIO,DC=LOCAL ldap_default_authtok = XXXXX_SENHA_DO_SSSD_XXXXX ldap_group_object_class = group ldap_id_mapping = True ldap_id_use_start_tls = True ldap_network_timeout = 5 ldap_referrals = False ldap_schema = ad ldap_search_base = DC=DOMINIO,DC=LOCAL ldap_sudo_search_base = DC=DOMINIO,DC=LOCAL ldap_tls_reqcert = never ldap_tls_cacert = /etc/ssl/private/sssd-ca.pem ldap_uri = ldaps://DC01.DOMINIO.LOCAL ldap_access_order = expire ldap_account_expire_policy = ad ldap_user_member_of = memberOf ldap_user_object_class = user ldap_force_upper_case_realm = True |
3.5.2. Controlando a execução do serviço
systemctl enable sssd # Ativa o início automático do serviço após o boot
systemctl start sssd # Inicia o serviço imediatamente
Solução para Reconhecimento Óptico de Caracteres (OCR)
F.A.Q
Dúvidas frequentes
Como adiciono um diretório além do CGTI para realização do OCR?
Crie o diretório em questão - recomenda-se seguir a estrutura atual, ou seja, /srv/shares/novoSetor/ocr/ - e crie o arquivo .watchmanconfig dentro de “entrada” com o texto {"settle": 10000}. Como também crie os diretórios "saída" e "originais". Após estas etapas, rode o comando de criação das triggers: Pronto, novo diretório para processamento OCR adicionado.
Como testar o OCR para um diretório que eu adicionei?
Apenas copie/envie o PDF para o servidor, fora do diretório .../ocr/entrada/. Então, logado no servidor via linha de comando, copie o PDF para dentro do diretório .../ocr/entrada que você criou anteriormente. O PDF será processado normalmente.
Existe algum log da solução OCR?
O arquivo de LOG presente em /var/log/ocr.log indica o estado de cada arquivo quanto ao seu processamento.
Como sei que o OCR está instalado?
Rode o comando: ocrmypdf --version
Deve aparecer um resultado similiar a: 5.7.0
Mensagens de comando não encontrado indicarão um problema na sua instalação, portanto, revise todas as etapas antes de continuar.
Como sei que o PDF está sendo processado no servidor?
O último estado no LOG para o arquivo em questão deve ser "Processando". Além disso, por meio do comando top, você deverá ver linha(s) com a execução de gs, tesseract ou ocrmypdf. Isto indica que um ou mais arquivos estão sendo processados.
Por que o processamento demora tanto em arquivos grandes?
Quanto maior o número de páginas ou características do documento escaneado, maior o tempo necessário para o processamento.
Existe alguma maneira de acelerar o processamento do PDF?
Incrementando a quantidade de cores e memória principal da sua VM é possível processar os arquivos PDFs em menor tempo.
O arquivo está recebido pela solução OCR mas não está sendo processado, o que pode estar acontecendo?
O watchman pode não estar ativo. Caso isso ocorra, rode o comando watchman watch-list e observe se os processamentos foram iniciados no log da solução OCR. Caso não haja entradas no log, verifique o log do watchman:
$ tail -f /usr/local/var/run/watchman/root-state/log.
Mensagens de erro podem ser consultadas no Google para dúvidas.
Caso o watchman esteja OK e ainda haja problemas para processar o arquivo, verifique se existe disco e memória suficientes para realizar esta operação.
Ao mover um arquivo PDF de dentro do próprio servidor, o OCR funciona. Mas enviando do meu usuário via rede (samba, sftp, outro meio) o OCR não acontece, o que posso verificar?
Problemas de permissão local. Siga as políticas definidas para o acesso aos diretórios e certifique-se de que ao enviar o PDF via rede, as permissões estejam adequadas e ajustadas para atender a sua política adotada no campus.
Adicionalmente, alguns softwares de envio de arquivos, ou mesmos os servidores de arquivos, possuem mecanismos para ajustar as permissões padrão para novos arquivos enviados.
Instalação da solução OCR
1. Introdução
Este documento visa a orientação para a instalação da solução OCR a ser utilizada no Instituto Federal de Pernambuco para reconhecimento óptico de caracteres em documentos digitalizados. Tal tecnologia permite a busca, indexação de arquivos PDF, como também assistência a deficientes visuais por meio de softwares assistivos.
Este documento está estruturado como se segue. A seção 2 descreve as características dos softwares utilizados para a solução, na seção 3 demonstra-se os procedimentos de instalação do OCRmyPDF e demais softwares. A seção 4 apresenta as configurações/modificações necessárias para o funcionamento do sistema, incluindo a configuração da impressora caso a TI opte por esta solução. Na seção 5 é demonstrado o uso da solução, e, finalmente, na seção 6 são apresentadas as referências utilizadas.
Características
- Processamento OCR;
- Texto em língua portuguesa do Brasil;
- Arquivos com saída PDF do tipo PDF/A-1b;
- Possibilidade de monitoramento de um ou mais diretórios de entrada;
- Processamento de PDFs mistos (com texto digital e texto escaneado);
- Processamento de documentos grandes (> 50 pag.);
- Manutenção dos arquivos PDF originais;
- Log para registro do processamento da solução OCR.
2. Softwares utilizados
O sistema operacional recomendado é o Debian a partir da versão 9.
OCRmyPDF
O OCRmyPDF realiza a leitura de documentos escaneados em PDF e permite o reconhecimento do seu texto. Assim, podendo ser buscado e indexado. Além disso, os documentos são automaticamente gerados em formato PDF/A, para arquivamento de longo prazo de documentos eletrônicos. O OCRmyPDF gera documentos no formato PDF/A-1b e PDF/A-2b.
Watchman
O Watchman permite monitorar determinado(s) diretório(s) com o objetivo de realizar operações quando os arquivos são modificados. É possível filtrar os tipos de arquivos com base no nome, tipo, dentre outras características.
Como o OCRmyPDF não funciona com base no esquema de cliente-servidor até o presente momento, é necessário um software como o Watchman para monitorar determinadas entradas e disparar comandos para executar o processamento dos arquivos inseridos ou modificados.
Na imagem seguinte, uma demonstração do fluxo de operação de todo o sistema caso a TI local opte pelo uso de um servidor de arquivos como o Samba.
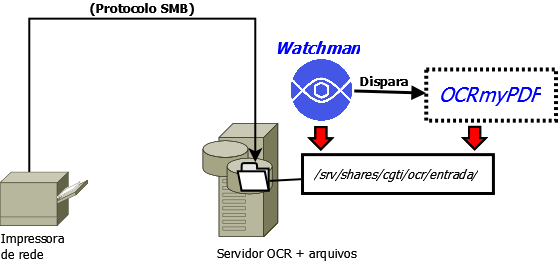
Na imagem seguinte, uma demonstração do fluxo de operação de todo o sistema caso a TI local opte pelo uso de um servidor de SFTP.
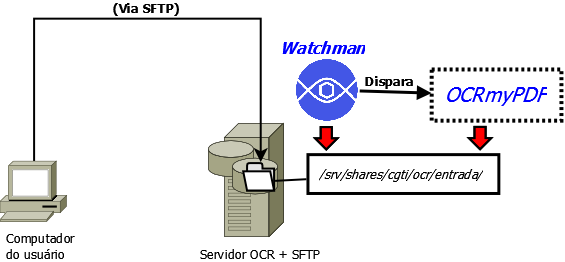
 O método de envio do arquivo para a pasta de entrada não está no escopo desta solução.
O método de envio do arquivo para a pasta de entrada não está no escopo desta solução.
Vozes NextUp-ScanSoft
Se desejar, este é um pacote de fala disponibilizado pela NextUp com uma voz feminina chamada Raquel. Este pacote é destinado ao uso nos clientes e não é necessária sua instalação no lado do servidor OCR. Atualmente, o software não faz mais parte do portfólio da empresa, mas a instalação é permitida e sem custos com o instalador disponível na Web. O pacote é utilizado por softwares como Adobe Reader e Foxit PDF Reader para a leitura do texto.
3. Instalação
OCRmyPDF
A última versão do OCRmyPDF disponível nos repositórios Debian/Ubuntu é bem anterior a versão já disponibilizada no repositório oficial dos desenvolvedores. Assim, não contempla as últimas atualizações necessárias ao bom funcionamento do pacote no que se refere a demanda de OCR do IFPE. Portanto, será demonstrada a instalação via compilação do código fonte.
Logado como root, execute os comandos:
$ apt-get update
$ apt-get install python3-pip
$ apt-get install libffi-dev
$ apt-get install tesseract-ocr
$ apt-get install ghostscript
$ apt-get install qpdf
$ apt-get install git
$ pip3 install git+https://github.com/jbarlow83/OCRmyPDF.gitPara dar suporte ao idioma Português do Brasil, instale o pacote abaixo:
$ apt-get install tesseract-ocr-por -yCom o OCRmyPDF instalado, faça o teste com algum arquivo PDF escaneado:
$ ocrmypdf entrada.pdf saida.pdf --output-type pdfa-1 -l por Os argumentos --output-type pdfa-1 -l por significam respectivamente o tipo de PDF/A gerado e o idioma a ser considerado na interpretação do texto presente no documento PDF.
Watchman
Ainda como root, instale alguns pacotes de dependência:
$ apt-get install gcc
$ apt-get install autoconf
$ apt-get install automake
$ apt-get install build-essential
$ apt-get install libtool
$ apt-get install libssl-dev
$ apt-get install pkg-config
$ apt-get install python-dev
$ apt-get install python3-devAgora procede-se a instalação do Watchman (como root):
$ git clone https://github.com/facebook/watchman.git
$ cd watchman
$ git checkout v4.9.0
$ ./autogen.sh
$ ./configure
$ make
$ make installNextUp-ScanSoft Raquel
Apenas baixe e instale o software (Windows) por meio do link abaixo:
|
https://drive.google.com/file/d/0B3aNFZuG_Yw9cjRCNUJBOUQ3QVk/view?usp=sharing |
Desinstalação
Caso seja necessário remover alguns dos softwares para manutenção/atualização, realize os seguintes comandos à seguir. Para remoção do OCRmyPDF:
$ pip3 uninstall ocrmypdfPara a remoção do Watchman, seria necessário excluir os binários, portanto, não se recomenda esta prática. Entretanto, caso necessite atualizar o Watchman, basta realizar a nova instalação que os binários serão sobrescritos com a nova versão.
4. Configuração
A configuração para a solução OCR fica praticamente com o Watchman e a impressora, já que a utilização do OCRmyPDF é bem simples. Considere a seguinte estrutura:
root@t-ifpe-ocr-beta:/# tree /srv
/srv
└── shares
├── ascom
│ └── ocr
│ ├── entrada
│ ├── originais
│ └── saida
├── cgti
│ └── ocr
│ ├── entrada
│ ├── originais
│ └── saida
└── dae
└── ocr
├── entrada
├── originais
└── saida
Watchman
O Watchman irá monitorar todos os diretórios “entrada” e dispara um script quando um novo arquivo PDF for criado. No exemplo abaixo, iremos criar três triggers. Para cada diretório “entrada”, crie o diretório e em seguida o seguinte arquivo de configuração do Watchman, exemplo para cgti:
$ mkdir -p /srv/shares/cgti/ocr/entrada/
$ mkdir -p /srv/shares/cgti/ocr/saida/
$ mkdir -p /srv/shares/cgti/ocr/originais/
$ nano /srv/shares/cgti/ocr/entrada/.watchmanconfig
{"settle": 10000}Sobre os diretórios criados, é importante trabalhar corretamente as permissões de usuário e grupo de acordo com o seu serviço de rede e políticas de acesso.
A função do arquivo .watchmanconfig é passar configurações específicas do diretório ao watchman. Neste caso, a opção "settle" impede que o PDF seja processado antes de sua completa transferência para o diretório. Crie em cada diretório "entrada" antes de executar o próximo comando de criação dos triggers.
Os triggers são criados e invocam o script no diretório /srv/ - o script pode estar em outro local, só necessita de permissão de execução do root. Crie as triggers:
$ watchman -- trigger /srv/shares/cgti/ocr/entrada/ 'ocrTrigCgti' '*.pdf' -- /srv/doOcr.sh
$ watchman -- trigger /srv/shares/dae/ocr/entrada/ 'ocrTrigDae' '*.pdf' -- /srv/doOcr.sh
$ watchman -- trigger /srv/shares/ascom/ocr/entrada/ 'ocrTrigAscom' '*.pdf' -- /srv/doOcr.shDetalhes:
Agora observe o script que está sendo utilizado, copie e cole no mesmo caminho, ou seja, /srv/doOcr.sh:
#!/bin/bash
# Escreve no log. Recebe o nome do arquivo e a ação realizada.
logIt(){
echo -e "$(date +%d/%m/%Y-%T)\t" $1"\t"$2 >> /var/log/ocr.log
}
# Realiza o OCR. Recebe o nome do arquivo de entrada.
ocrFile(){
logIt "$arg" "Processando"
filename=$(echo "$1" | cut -f 1 -d '.') # sem extensão
entrada="$1"
saida="$filename"-ocr.pdf
ocrmypdf "$entrada" ../saida/"$saida" -l por --output-type pdfa-1 --skip-text
chmod g=rw,o= ../saida/"$saida"
logIt "$arg" "OCR realizado"
mv "$arg" ../originais
}
# Fluxo principal
for arg in "$@"
do
if [ -f "$arg" ]; # arquivo existe ?
then
logIt "$arg" "Arquivo recebido"
ocrFile "$arg" &
fi
doneCaso copie e cole o script acima, antes, edite o texto e organize as linhas e aspas duplas (“ ”).
Dê permissões de execução para o script.
$ chmod +x /srv/doOcr.shAtivando a auto-inicialização
O watchman deve monitorar os diretórios assim que o S.O. for iniciado. De forma a permitir que esta função seja realizada, deve-se adicionar o comando de inicialização do watchman aos comandos executados após o início do S.O.
Para realizar isto, basta seguir o tutorial de scripts de inicialização com system V que está na WIKI do IFPE. Atente para as variáveis do script que neste caso do watchman devem ser:
dir="/usr/local/bin/"
cmd="watchman -f"
user="root"
Impressora
Será demonstrada configuração na impressora Kyocera FS-1135 enviando o PDF para um servidor de arquivos. Para outras impressoras, as configurações são semelhantes, com algumas pequenas diferenças que podem ocorrer na forma como o S.O. da impressora trata os dados inseridos.
A impressora deve estar conectada diretamente à rede.
Acesse o painel WEB da impressora:

Serão criados “contatos” na agenda da impressora com configurações pré-definidas para salvar os documentos escaneados. Desta forma, evita-se a inserção manual das configurações de acesso ao servidor de arquivos. Na Kyocera, por exemplo, um contato pode conter informações FTP, SMB e de e-mail para o envio do PDF gerado.

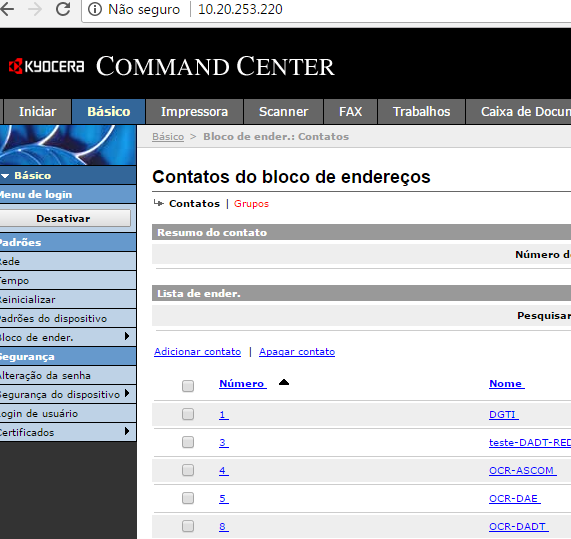
Tem-se várias opções de envio, será escolhido o protocolo SMB.

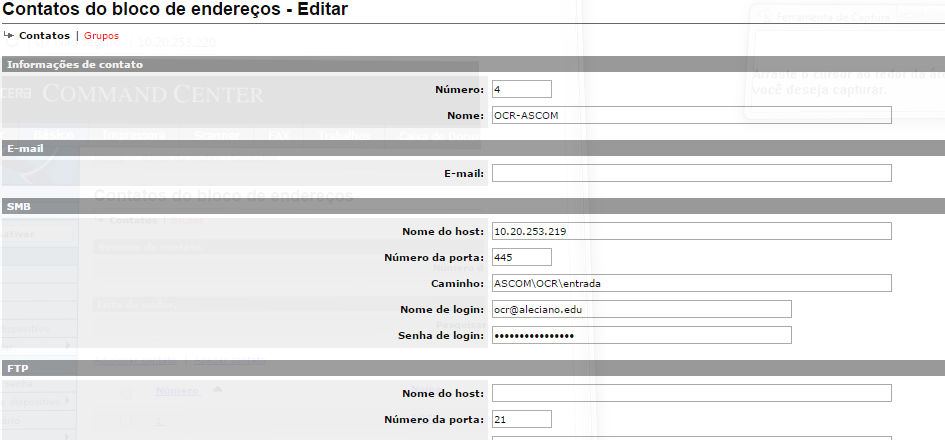
-
Nome de host: IP ou hostname do servidor de arquivos;
-
Número da porta: porta que o servidor de arquivos escuta para receber arquivos;
-
Caminho: utilizando contra-barras, o nome do compartilhamento seguido dos sub-diretórios para onde serão enviados os arquivos PDF;
-
Nome de login: usuário e DOMÍNIO no formato usuario@dominio. Recomenda-se a criação de um usuário no seu domínio para cada impressora.
-
Senha de login: senha do usuário no DOMÍNIO.
Clicar em Enviar para salvar as configurações. Posteriormente, para escanear e mandar para o servidor de arquivos, seguir as próximas configurações.
Envio dos arquivos
A configuração do envio dos arquivos foge do escopo deste tutorial. Mas o importante é que os usuários criados para o envio dos arquivos tenham permissões de escrita (write) no diretório “entrada” configurado. O script (/srv/doOcr.sh) deve ter configurações de execução habilitadas para que o Watchman consiga dispará-lo, bem como os usuários do domínio devem ter no mínimo acesso de leitura no diretório de “saída”.
Recomenda-se uma política de manutenção dos arquivos que ficarão no diretório originais. Pode-se movê-los para um backup ou executar algum script periódico para limpar arquivos antigos.
LOG
O log de processamento dos arquivos da solução OCR se encontrará disponível no caminho /var/log/ocr.log. O estado possíveis para arquivo é:
- Arquivo recebido - o arquivo foi recebido e detectado pelo watchman que já invocou o script doOcr.sh.
- Processando - o OCRmyPDF está processando o arquivo.
- OCR realizado. - o arquivo foi processado pelo OCRmyPDF com sucesso e movido para o diretório “saida”.
5. Atualização a partir de uma versão anterior
Se já existia uma versão anterior da solução OCR implantada, basta realizar a atualização de alguns pontos.
Atualize o OCRmyPDF:
$ apt-get update
$ apt-get install python3-pip
$ apt-get install libffi-dev
$ apt-get install tesseract-ocr
$ apt-get install ghostscript
$ apt-get install qpdf
$ apt-get install git
$ pip3 install git+https://github.com/jbarlow83/OCRmyPDF.git@v5.7.0
$ apt-get install tesseract-ocr-por -yDelete as triggers antigas do watchman, exemplo para cgti:
$ watchman watch-del /srv/shares/cgti/ocr/entradaCrie o arquivo .watchmanconfig no(s) diretório(s) de entrada do OCR, exemplo para cgti:
$ nano /srv/shares/cgti/ocr/entrada/.watchmanconfig
{"settle": 10000}Faça uma cópia e atualize o script de execução doOcr.sh para esta versão abaixo:
$ cp /srv/doOcr.sh /srv/doOcr.sh-bkp
$ nano /srv/doOcr.sh
<<<<<<<<<insira o conteúdo abaixo>>>>>>>>>>>>>>>>>>>>>>>
#!/bin/bash
# Escreve no log. Recebe o nome do arquivo e a ação realizada.
logIt(){
echo -e "$(date +%d/%m/%Y-%T)\t" $1"\t"$2 >> /var/log/ocr.log
}
# Realiza o OCR. Recebe o nome do arquivo de entrada.
ocrFile(){
logIt "$arg" "Processando"
filename=$(echo "$1" | cut -f 1 -d '.') # sem extensão
entrada="$1"
saida="$filename"-ocr.pdf
ocrmypdf "$entrada" ../saida/"$saida" -l por --output-type pdfa-1 --skip-text
chmod g=rw,o= ../saida/"$saida"
logIt "$arg" "OCR realizado"
mv "$arg" ../originais
}
# Fluxo principal
for arg in "$@"
do
if [ -f "$arg" ]; # arquivo existe ?
then
logIt "$arg" "Arquivo recebido"
ocrFile "$arg" &
fi
doneCrie novamente as triggers do watchman, exemplo para cgti:
$ watchman -- trigger /srv/shares/cgti/ocr/entrada/ 'ocrTrigCgti' '*.pdf' -- /srv/doOcr.sh6. Operação com scanner
Aqui é demonstrado o envio dos arquivos de uma impressora para o servidor de arquivos local.
Scanner


Apertar o botão “Enviar”.


Apertar o botão de contatos, ou “Libro de direcciones” como neste caso. Tem a função de acesso a Agenda.


Selecione o contato previamente salvo na agenda e apertão o botão “Ok”.

Aperte “Ok” para confirmar o endereço. Em seguida, apertar o botão verde principal para dar início a digitalização.

Se não aparecer nenhuma mensagem de erro ou o LED vermelho não piscar, houve sucesso no escaneamento.
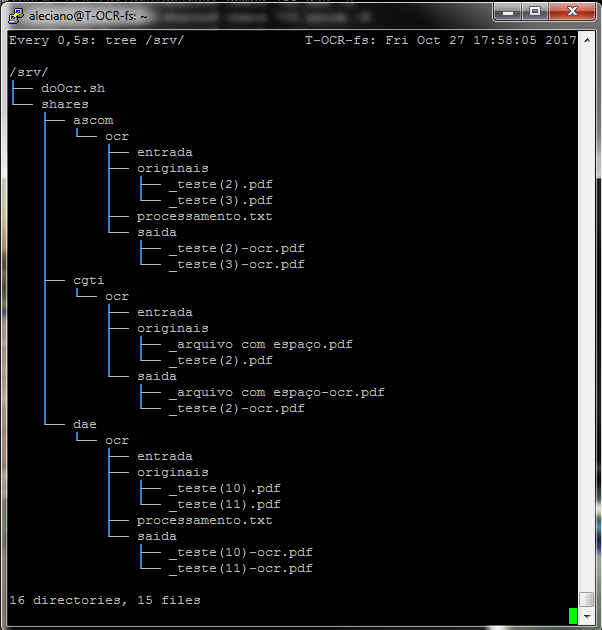
Diretório “Ascom”, na estrutura, indicando sucesso no escaneamento e no processamento OCR.
O OCRmyPDF pode levar alguns minutos para processar o arquivo PDF.
Visualização (texto)
O arquivo com reconhecimento OCR e padrão PDF/A-1b ou 2b, aparece da seguinte forma em softwares como Adobe Reader. Como é possível notar, o texto é selecionável.
Visualização (áudio da leitura)
Utilizando o software Adobe Reader como exemplo, acesse as Preferências do software, ative o recurso de Leitura do texto e selecione a voz “Raquel” para uso.
Para escutar a leitura do texto pelo software, pressione os atalhos Shift + Ctrl + Y (Ativar leitura em voz alta) e Shift + Ctrl + B (Ler todo o documento). Também, é possível escutar clicando no texto ou percorrendo com o cursor do mouse.
Leitura do arquivo com OCR em ação:


https://www.youtube.com/watch?v=xrBu4fhoXFE&feature=youtu.be
7. Referências
https://pt.wikipedia.org/wiki/PDF/A
https://softwarepublico.gov.br/archives/thread/sei-negocio/como-criar-pdfa-conforme-iso-19005-12005
https://ocrmypdf.readthedocs.io/en/latest/index.html
http://facebook.github.io/watchman/
https://stackoverflow.com/questions/1659147/how-to-use-ghostscript-to-convert-pdf-to-pdf-a-or-pdf-x
https://www.pdf-online.com/osa/validate.aspx
http://www.tecassistiva.com.br/servicos?id=105
Solução OCR em OVA
Introdução
Este documento visa a orientação sobre as configurações aplicadas na máquina virtual (VM) da solução OCR versão 1.2.1 Serão apresentadas as configurações de sistema, particionamento, rede, usuários e particularidades da solução OCR.
As CGTIs devem alterar configurações para satisfazer suas necessidades locais. A DADT entrega uma versão simplificada e funcional, com exemplos, demonstrando o serviço. À partir da entrega da VM, a CGTI fica responsável por sua manutenção e uso. Não se responsabilizando a DADT por eventuais problemas decorridos de alterações realizadas pelas coordenações locais de TI dos campi.
Características da VM
- VM Version: 8
- CPU: 2 vCPU
- Memória: 1024 MB
- Disco provisionado: 5 GB
O tamanho do disco é pequeno para facilitar o download e implantação da solução. Recomenda-se fortemente que o disco seja expandido para evitar falta de espaço em algumas partições.
- Sistema operacional: Debian 9.1, 64 Bits
- Sistema de armazenamento: LVM (Logical Volume Management). Utilizado por permitir flexibilidade na extensão das partições – útil para quando os discos ficam cheios e for necessário expandi-lo.
O volume físico está em /dev/sda5:
|
$ sudo pvs |
|
PV VG Fmt Attr PSize PFree /dev/sda5 linux lvm2 a-- 4,52g 0 |
Apresenta grupo de volumes (linux) com um volume físico e três volumes lógicos:
|
$ sudo vgs |
|
VG #PV #LV #SN Attr VSize VFree linux 1 3 0 wz--n- 4,52g 0 |
Volumes lógicos são root, srv e swap:
|
$ sudo lvs |
|
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert root linux -wi-ao---- 3,11g srv linux -wi-ao---- 956,00m swap linux -wi-ao---- 488,00m |
Visão geral do sistema de arquivos:
|
$ df -hP |
|
Sist. Arq. Tam. Usado Disp. Uso% Montado em udev 487M 0 487M 0% /dev tmpfs 100M 4,6M 96M 5% /run /dev/mapper/linux-root 3,0G 2,2G 725M 75% / tmpfs 499M 0 499M 0% /dev/shm tmpfs 5,0M 0 5,0M 0% /run/lock tmpfs 499M 0 499M 0% /sys/fs/cgroup /dev/mapper/linux-srv 925M 2,4M 859M 1% /srv /dev/sda1 472M 37M 411M 9% /boot tmpfs 100M 0 100M 0% /run/user/1000 |
- Configurações de rede. Os IPs devem ser trocados de acordo com a rede de cada campi:
|
$ nano /etc/network/interfaces |
|
# A interface de loopback auto lo iface lo inet loopback # A interface de rede primaria auto ens33 allow-hotplug ens33 iface ens33 inet static address 172.16.1.10/24 gateway 172.16.1.1 dns-nameservers 172.16.1.6 dns-search ifpe.edu.br |
Informações das interfaces:
|
$ ip a |
|
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:94:08:8d brd ff:ff:ff:ff:ff:ff inet 172.16.1.10/24 brd 172.16.1.255 scope global ens33 valid_lft forever preferred_lft forever |
- Usuários ativos. Sugere-se a troca das senhas:
|
Usuário |
Senha |
|
cgti |
*@tif0cr |
|
root |
&_p0i3TJ |
Grupos ativos:
|
Grupo |
Usuário membro |
|
cgti |
cgti |
|
root |
root, cgti |
|
sudo |
root, cgti |
- O diretório mapeado como exemplo para OCR é /srv/shares/cgti/ocr/entrada/. A CGTI deve criar os novos diretórios e mapeamentos de acordo com a sua necessidade.
A estrutura dos diretórios:
|
$ tree /srv |
|
/srv └── shares ├── cgti └── ocr ├── entrada ├── originais └── saida |
Trigger do Watchman criada para o diretório em questão:
|
$ cat /usr/local/var/run/watchman/root-state/state |
|
{ "watched": [ { "triggers": [ { "command": [ "/srv/doOcr.sh" ], "expression": [ "anyof", [ "match", "*.pdf", "wholename" ] ], "stdin": [ "name", "exists", "new", "size", "mode" ], "name": "ocrTrigCgti", "append_files": true } ], "path": "/srv/shares/cgti/ocr/entrada" } ], "version": "4.9.0" } |
Arquivo do Watchman para configuração presente de forma obrigatória no diretório “entrada”:
|
$ cat /srv/shares/cgti/ocr/entrada/.watchmanconfig |
|
{"settle": 10000} |
Como importar a VM no ambiente VMWARE
Neste método de importação será utilizado o ambiente vSphere Client versão 6.0.0, disponível em https://kb.vmware.com/s/article/2089791. O ESXi utilizado é da versão 6.5.0. Certifique-se de ter instalado o vSphere Client na sua máquina para ter sucesso neste método.
Baixe a OVA: https://drive.google.com/file/d/1E20S31VW41_Pu9jc_MTfURKJRmmmmi2C/view?usp=sharing
Realize o login no ambiente com suas credenciais:
Após logar, clique em File e em seguida, clique Deploy OVF Template:
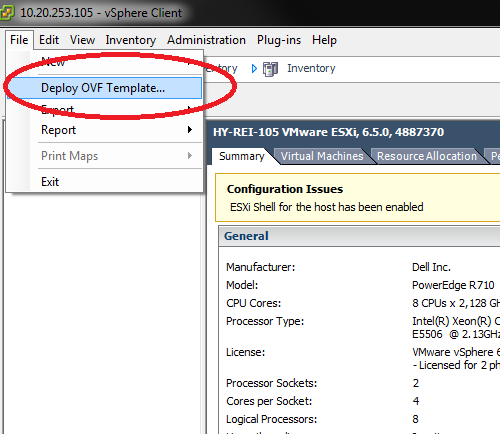
Na próxima janela, clique em Browse para procurar o arquivo OVA:
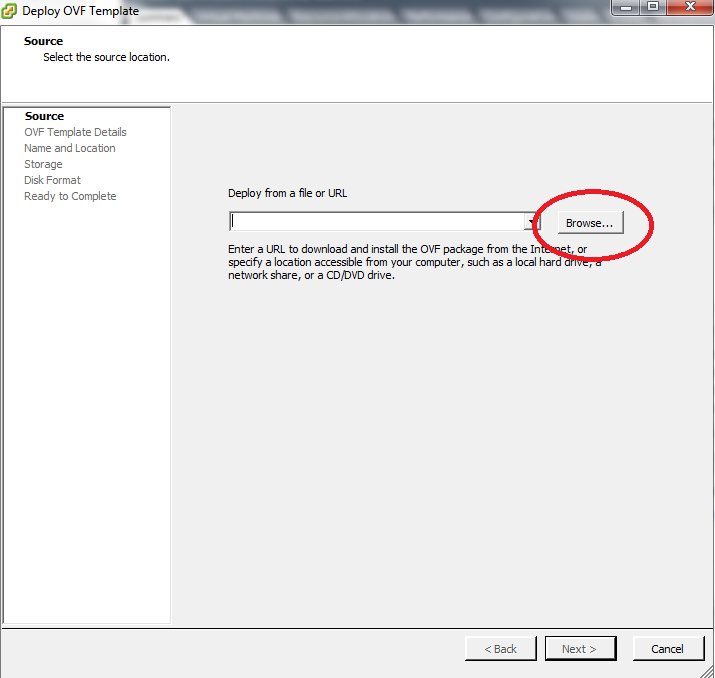 <>
<>
Selecione o arquivo e clique em Abrir:

Na próxima janela clique em Next, e observe os detalhes da VM:
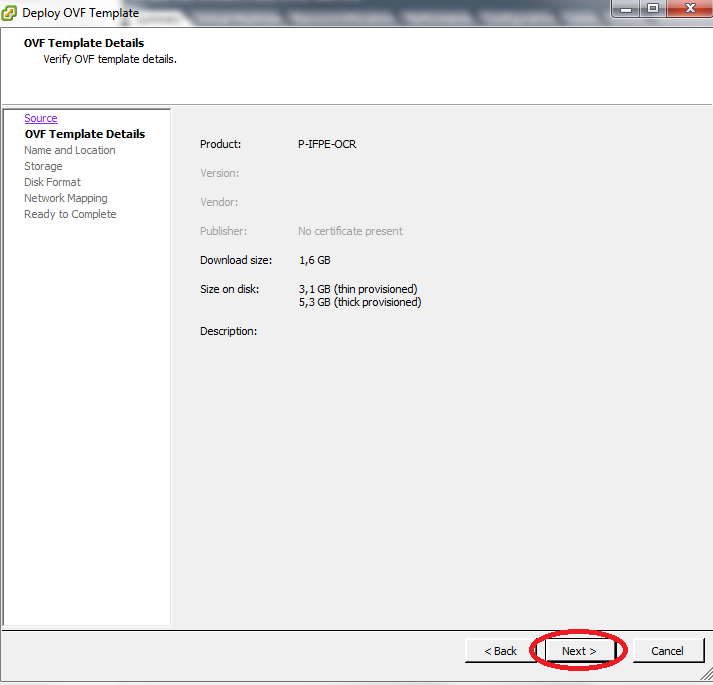
Selecione o nome desejado para VM e clique em Next.
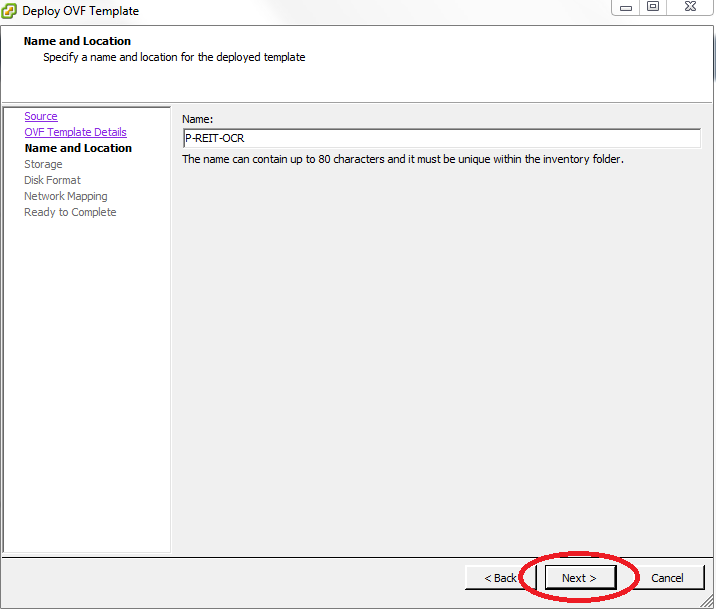
Selecione o storage do ESXi no qual os arquivos do objeto da VM serão armazenados e clique Next. Na janela seguinte, clique Next mais uma vez.
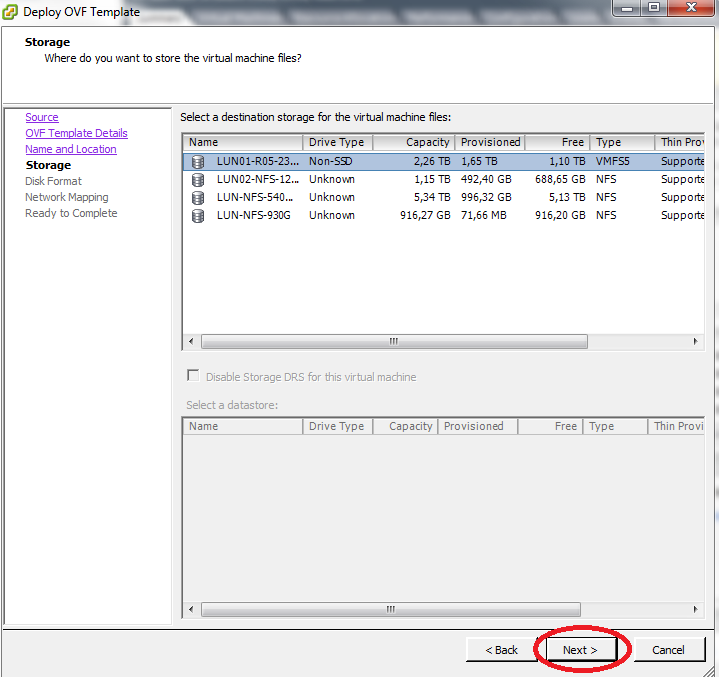
Agora realize o mapeamento da rede interna criada no ESXi. Na coluna Destination Networks deverá existir o nome da rede aplicada no ESXi local, selecione apropriadamente de acordo com o seu ambiente. No caso em tela, a rede de destino possui o mesmo nome.

Estamos quase lá, agora observe as configurações selecionadas. Clique em Finish quando tiver certeza do que será aplicado.
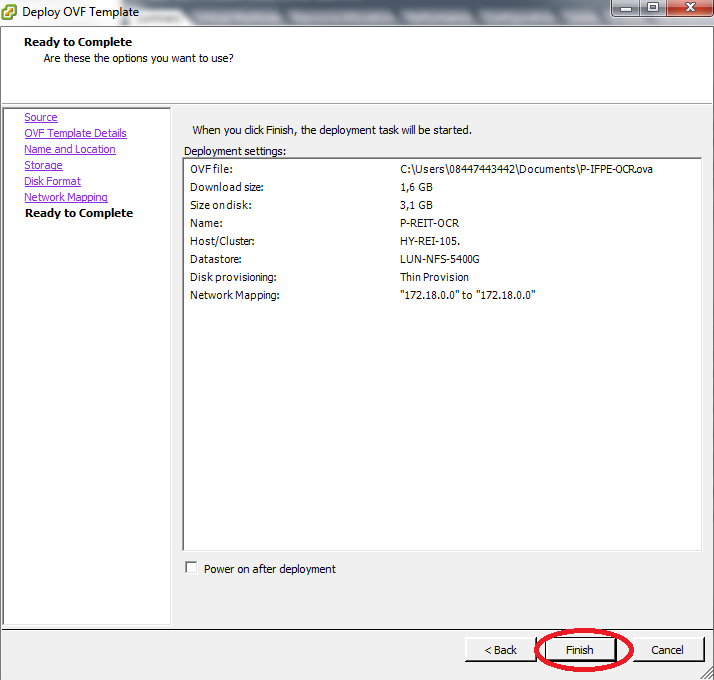
A VM começará a ser importada:
A operação pode levar algum tempo. A seguinte tela surge quando concluído.

Pronto, a VM está pronta para uso.